


Intel Gaudiは、NVIDIAとAMDに対抗するIntelのAIアクセラレータです。Gaudi 3は、H100に匹敵する性能を低価格で提供し、AI開発のコスト削減を実現。本記事では、Gaudiシリーズのスペック、価格、導入事例、NVIDIA・AMDとの比較を徹底解説します。
Intel Gaudiとは
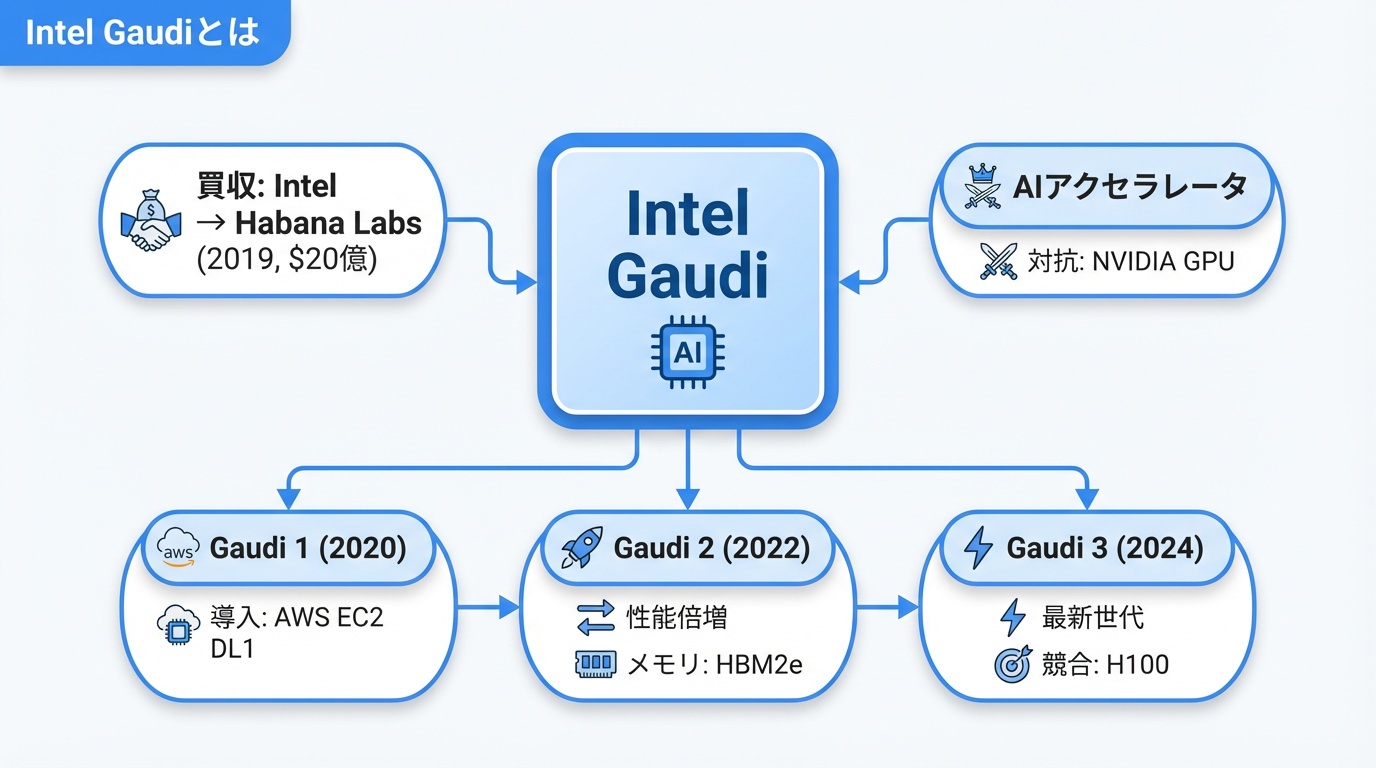
Intel Gaudiは、Intelが開発するAI学習・推論専用のアクセラレータです。2019年にIntelが買収したイスラエルのHabana Labs社の技術を基盤としており、NVIDIAのGPU独占市場に挑戦する戦略製品として位置づけられています。
Habana Labsの買収背景
Intelは2019年、約20億ドルでHabana Labsを買収しました。当時、AIアクセラレータ市場はNVIDIAが支配しており、IntelはXeon PhiやFPGAでの参入を試みていましたが、成功には至っていませんでした。Habana Labsの買収により、AI専用チップの開発能力を獲得しました。
Gaudiシリーズの進化
- Gaudi 1(2020年):初代製品。AWS EC2 DL1インスタンスで提供
- Gaudi 2(2022年):性能2倍向上。HBM2eメモリ搭載
- Gaudi 3(2024年):最新世代。H100に対抗する性能
Gaudi 3のスペック詳細
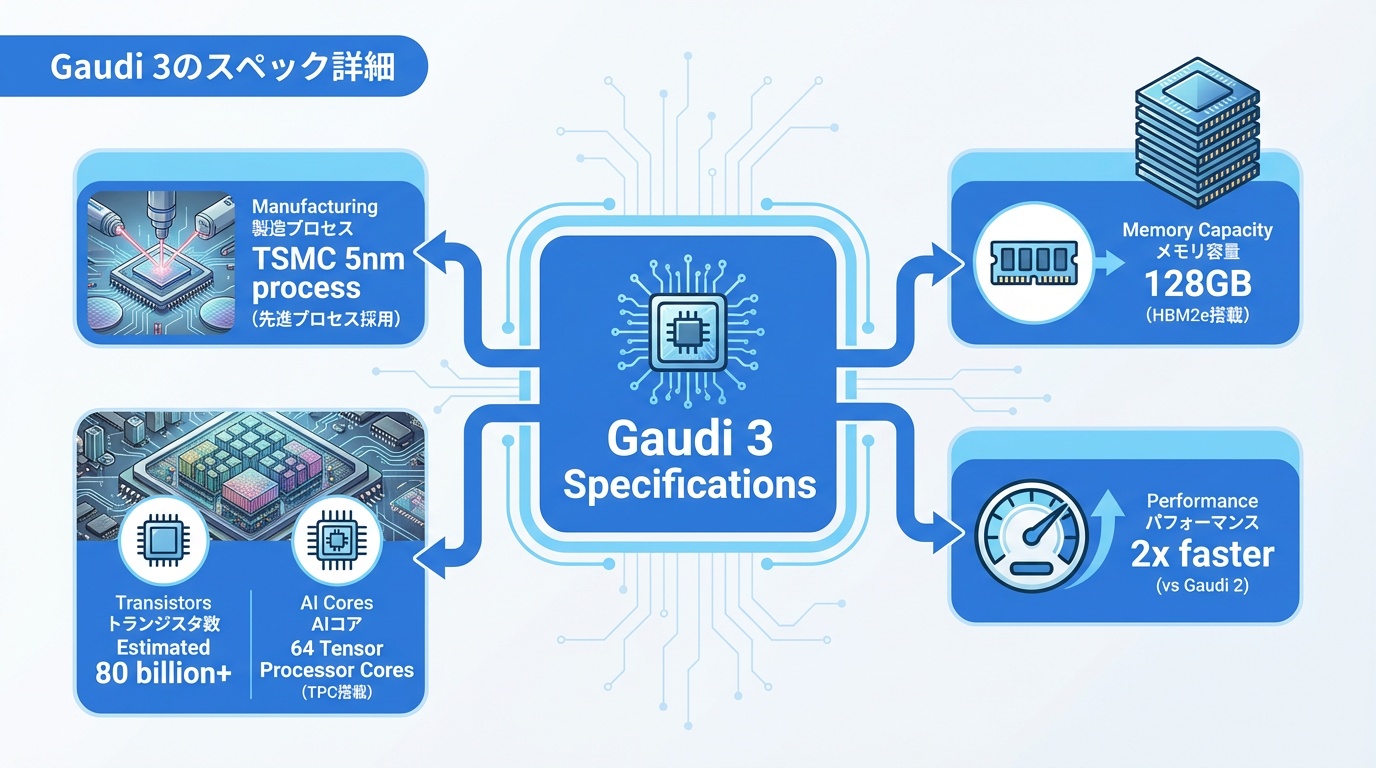
2024年発表の最新世代Gaudi 3の詳細スペックを解説します。
基本仕様
- 製造プロセス:TSMC 5nm
- トランジスタ数:非公開(推定800億個以上)
- AI演算コア:64 Tensor Processor Cores(TPC)
- 行列演算エンジン:8基
- TDP:600W(SXM版)/ 450W(PCIe版)
メモリ構成
- HBM2e:128GB(8スタック)
- メモリ帯域:3.7TB/s
メモリ容量はNVIDIA H100(80GB)の1.6倍。大規模言語モデルの推論に有利です。
AI演算性能
- FP8学習:1,835 TFLOPS
- BF16学習:917 TFLOPS
- FP8推論:1,835 TOPS
IntelはGaudi 3がH100比で「学習で50%、推論で2倍高速」と主張しています。
ネットワーク接続
- 内蔵ネットワーク:24 × 200Gbps RoCEポート
- 総帯域:4.8Tb/s
Gaudiシリーズの特徴は、ネットワーク機能をチップに内蔵している点です。InfiniBandのような外部スイッチなしでマルチノードスケーリングが可能です。
Gaudi 2のスペックと現状
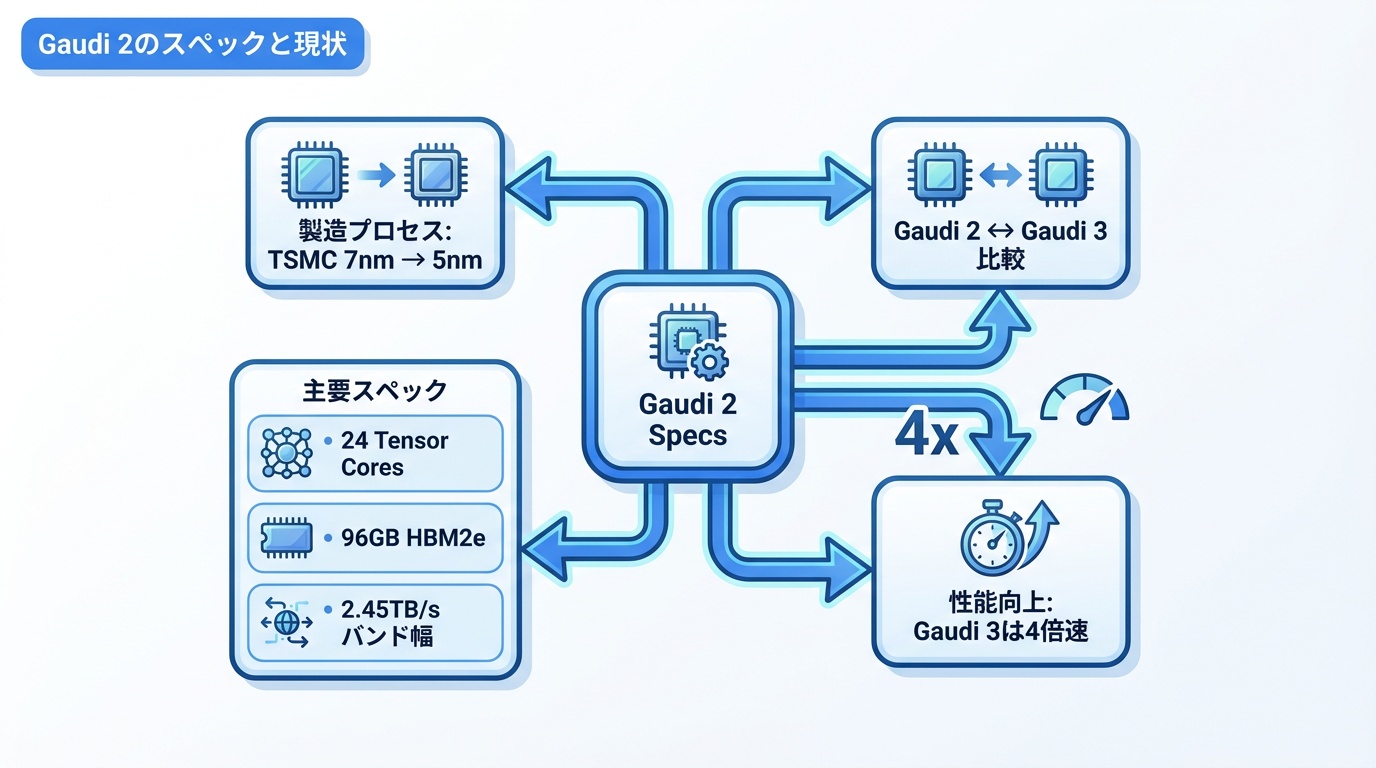
Gaudi 2は現在も広く利用されている製品です。Gaudi 3との比較のため、スペックを紹介します。
基本仕様
- 製造プロセス:TSMC 7nm
- AI演算コア:24 Tensor Processor Cores
- メモリ:96GB HBM2e
- メモリ帯域:2.45TB/s
- TDP:600W
性能比較
Gaudi 3はGaudi 2比で約4倍の性能向上を実現。プロセス微細化(7nm→5nm)とアーキテクチャ改良により、大幅な性能向上を達成しています。
NVIDIA H100・AMD MI300Xとの比較
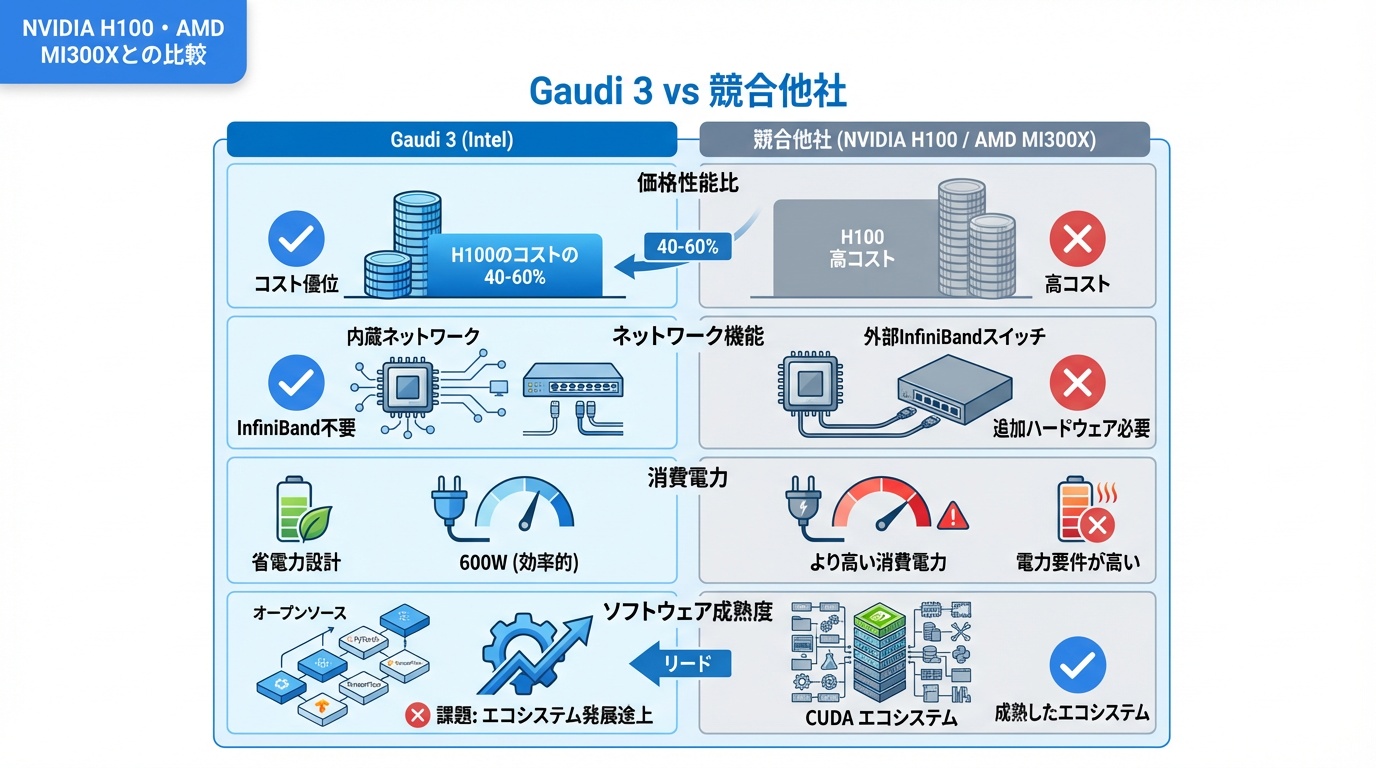
Gaudi 3と競合製品を詳細比較します。
| 項目 | Intel Gaudi 3 | NVIDIA H100 | AMD MI300X |
|---|---|---|---|
| メモリ容量 | 128GB HBM2e | 80GB HBM3 | 192GB HBM3 |
| メモリ帯域 | 3.7TB/s | 3.35TB/s | 5.3TB/s |
| FP8性能 | 1,835 TFLOPS | 1,979 TFLOPS | 2,614 TFLOPS |
| TDP | 600W | 700W | 750W |
| ネットワーク | 内蔵RoCE | 外部NVLink | 外部Infinity Fabric |
| 価格(推定) | $10,000〜15,000 | $25,000〜40,000 | $15,000〜20,000 |
| ソフトウェア | Habana SynapseAI | CUDA | ROCm |
Gaudi 3の優位点
- 価格性能比:H100の約40〜60%の価格で同等性能
- 内蔵ネットワーク:InfiniBandスイッチ不要でコスト削減
- 消費電力:600Wで競合より省電力
- Intel エコシステム:Xeonとの統合、oneAPI対応
Gaudi 3の課題
- ソフトウェア成熟度:CUDAエコシステムに大きく劣る
- 実績:大規模LLM学習での採用実績が少ない
- 入手性:供給体制がNVIDIAほど確立されていない
ソフトウェアエコシステム
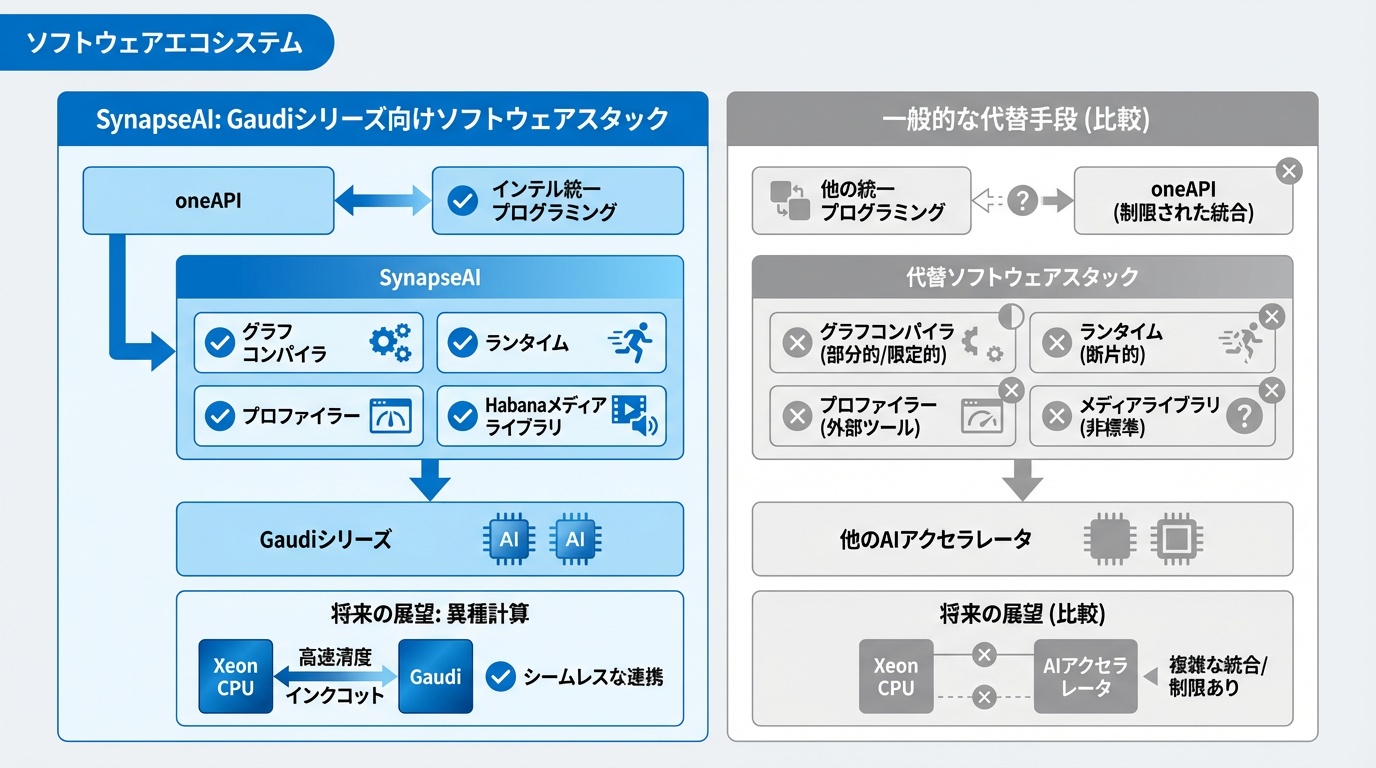
Gaudiの価値を最大化するソフトウェアスタックを解説します。
Habana SynapseAI
SynapseAIは、Gaudiシリーズ専用のソフトウェアスタックです。以下のコンポーネントで構成されています。
- Graph Compiler:計算グラフの最適化・コンパイル
- Runtime:実行環境とメモリ管理
- Profiler:性能分析ツール
- Habana Media Library:データ前処理
フレームワーク対応
- PyTorch:habana_frameworks.torch 経由で対応
- TensorFlow:公式サポート
- Hugging Face:Optimum-Habana で統合
- DeepSpeed:分散学習対応
oneAPIとの統合
IntelのoneAPIフレームワークとの統合が進んでいます。oneAPIはIntelのCPU、GPU、FPGA、AIアクセラレータを統一的にプログラミングできる環境です。将来的には、Xeon CPUとGaudiを組み合わせたヘテロジニアスコンピューティングが容易になる見込みです。
主要クラウドでの提供状況
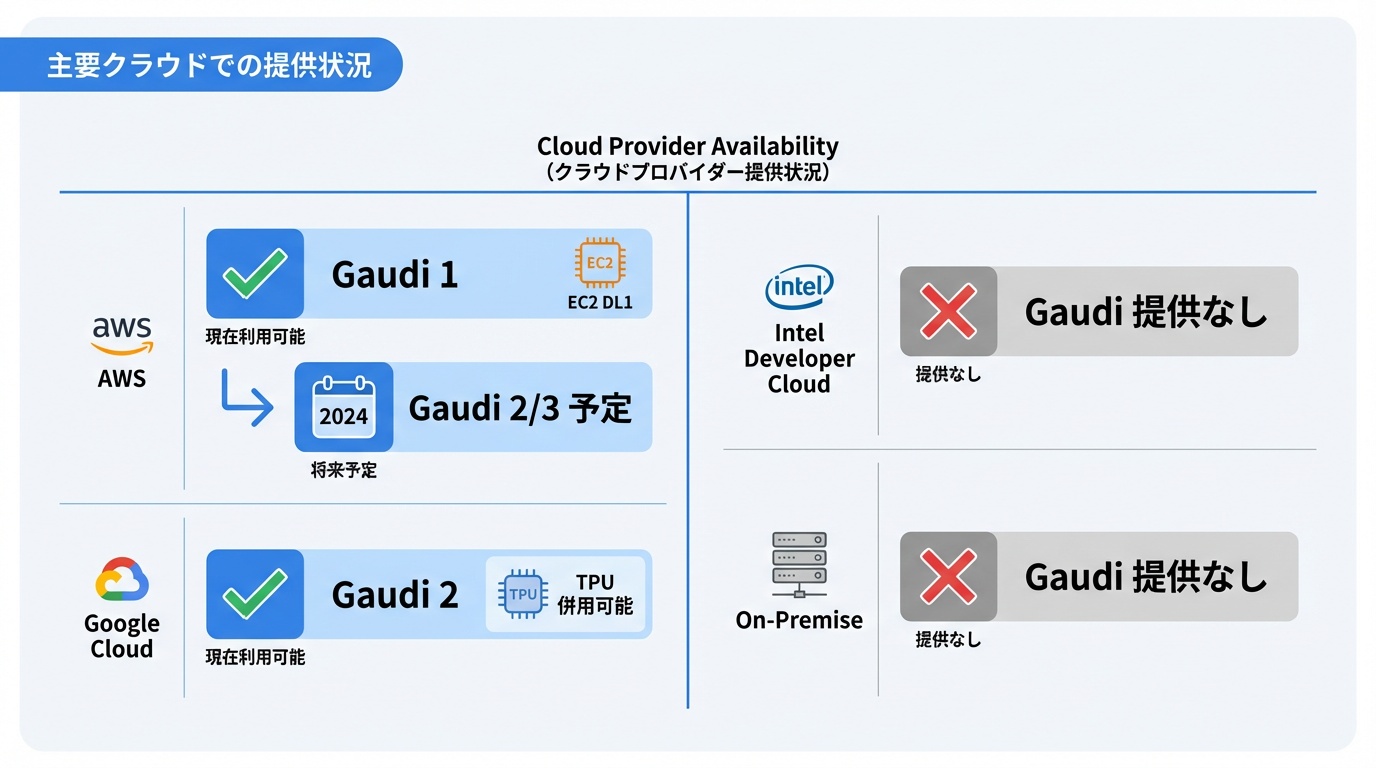
Gaudiシリーズは複数のクラウドプロバイダーで利用可能です。
AWS
Amazon EC2 DL1インスタンスでGaudi 1を提供。2024年以降、Gaudi 2/3対応インスタンスの追加が予定されています。AWSはIntelと戦略的提携を結んでおり、Gaudi採用を拡大する方針です。
Google Cloud
Google Cloud上でGaudi 2を利用可能。TPUとの棲み分けを図りつつ、Intel環境を好む顧客向けに提供しています。
Intel Developer Cloud
Intel自身が運営するクラウドサービスで、Gaudi 2/3を時間課金で利用可能。開発者向けの無料枠も提供されています。
オンプレミス
Dell、HPE、Supermicroなどから、Gaudi搭載サーバーを購入可能。Intelはリファレンスデザインを公開しており、サーバーベンダーが採用しやすい環境を整備しています。
導入事例と採用企業
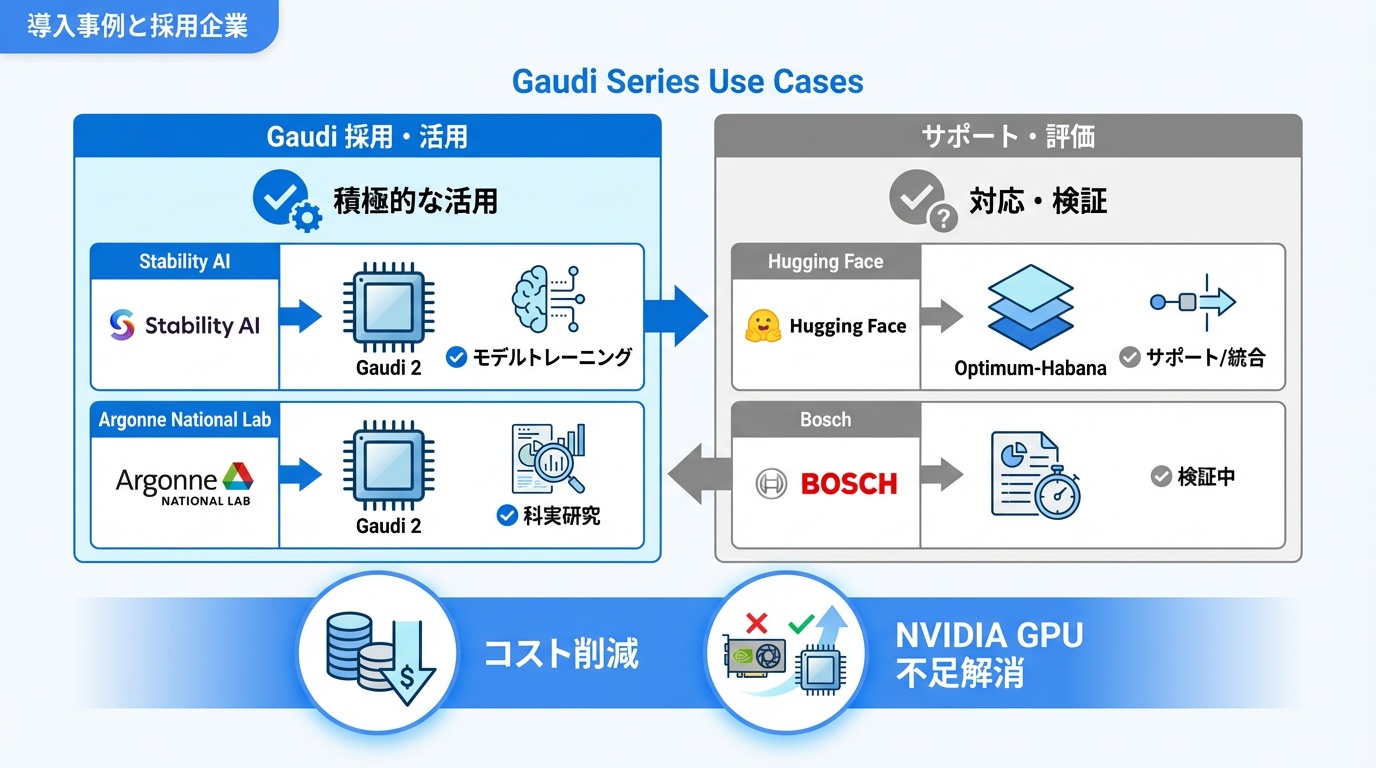
Gaudiシリーズの主要な導入事例を紹介します。
Stability AI
画像生成AI「Stable Diffusion」を開発するStability AIは、Gaudi 2でのモデル学習を実施。NVIDIA GPU不足への対応と、コスト削減の両面でGaudiを評価しています。
Hugging Face
AI開発プラットフォームのHugging Faceは、Optimum-Habanaを通じてGaudiサポートを提供。Transformersライブラリとの統合により、多くのモデルをGaudiで実行可能です。
ボッシュ
自動車部品大手のボッシュは、自動運転AI開発にGaudiを採用。Intelとの長年の提携関係を活かし、AI研究開発基盤を構築しています。
アルゴンヌ国立研究所
米国のアルゴンヌ国立研究所は、科学シミュレーション向けにGaudi 2を導入。Aurora スーパーコンピュータでのIntel GPU(Max GPU)との組み合わせも検討されています。
価格と入手方法
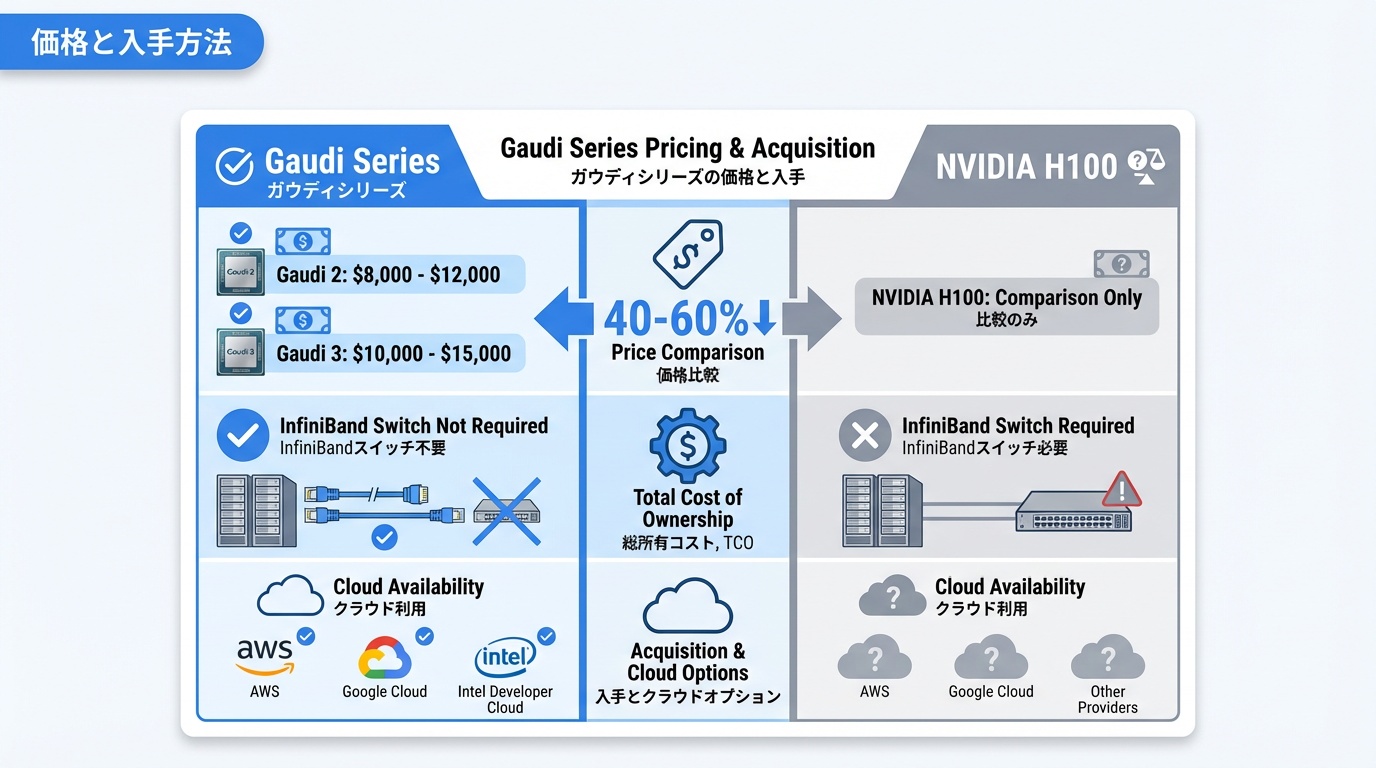
Gaudiシリーズの価格と入手方法を解説します。
価格帯
- Gaudi 2:推定$8,000〜12,000/台
- Gaudi 3:推定$10,000〜15,000/台
NVIDIA H100($25,000〜40,000)と比較して、40〜60%安価です。TCO(総所有コスト)で見ると、内蔵ネットワークによりInfiniBandスイッチが不要な分、さらにコスト優位性があります。
入手方法
- クラウド:AWS、Google Cloud、Intel Developer Cloudで時間課金利用
- サーバーベンダー:Dell PowerEdge、HPE ProLiant、Supermicroサーバー
- Intel直販:大口顧客向け
導入検討のポイント
Gaudi導入を検討する際は、以下の点を考慮してください。
- ワークロード:PyTorch/TensorFlowベースの学習・推論に最適
- 規模:中規模クラスター(8〜64ノード)で特にコスト優位
- ソフトウェア要件:CUDA依存が少ないプロジェクトに適合
- サポート:Intelの技術サポートが受けられる体制が重要
今後のロードマップ
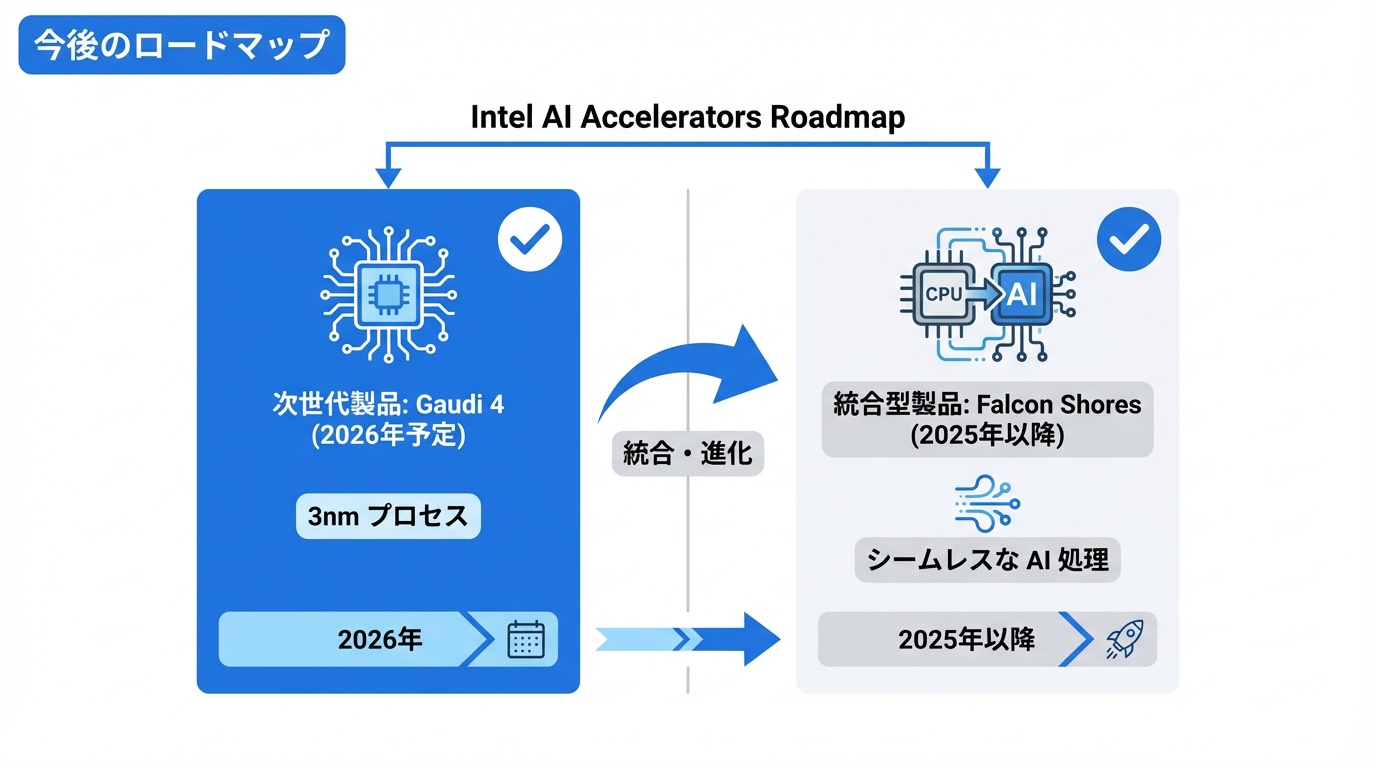
Intel AIアクセラレータの今後の展開を解説します。
Gaudi 4(2026年予定)
次世代Gaudi 4は、3nm プロセスへの移行と、性能のさらなる向上が予定されています。NVIDIA Blackwellに対抗する製品となる見込みです。
Falcon Shores(統合製品)
Intelは、CPUとAIアクセラレータを統合した「Falcon Shores」を開発中。XeonとGaudiの機能を1チップに統合し、シームレスなAI処理を実現する計画です。2025年以降の投入が予定されています。
ソフトウェア強化
oneAPIの機能拡充、PyTorch/Hugging Faceとの統合強化、CUDAコード移行ツールの改善が継続的に進められています。
よくある質問
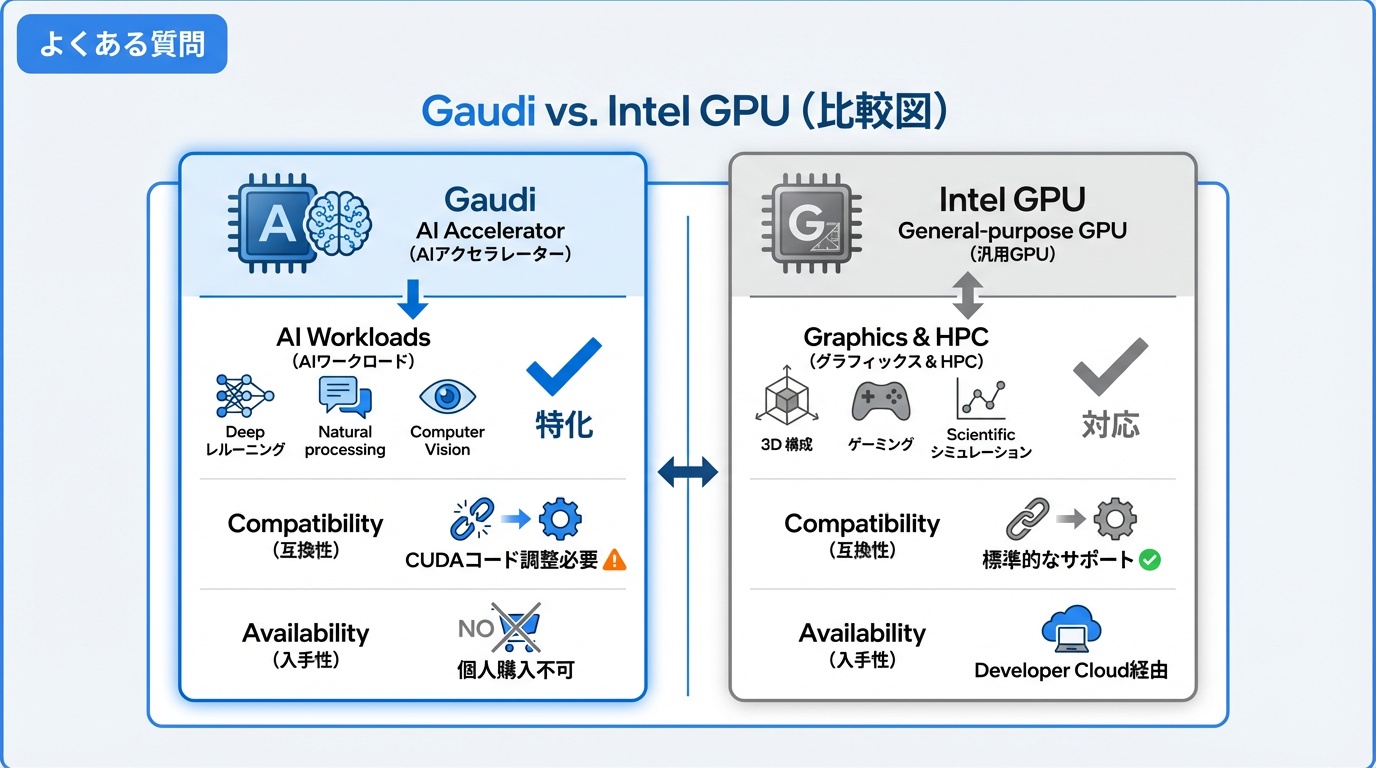
Q. GaudiとIntel GPUの違いは何ですか?
Gaudiは「AIアクセラレータ」で、AI学習・推論に特化しています。Intel GPU(Arc、Max GPU)は「汎用GPU」で、グラフィックス処理やHPCワークロードも対象です。純粋なAIワークロードにはGaudi、グラフィックス併用ならIntel GPUが適しています。
Q. CUDAで書かれたコードはGaudiで動きますか?
直接は動きません。PyTorchやTensorFlowを使用している場合は、habana_frameworksに切り替えることで多くのコードが動作します。高度なCUDAカーネルを使用している場合は、書き換えが必要です。
Q. 個人で購入できますか?
Gaudiはデータセンター向け製品であり、個人向け販売は行われていません。個人でIntel AIを試したい場合は、Intel Developer Cloudの無料枠を利用するか、Intel Arc GPUを検討してください。
Q. NVIDIAからの移行は簡単ですか?
ワークロードによります。Hugging Face Transformersを使用している場合は、Optimum-Habanaで比較的容易に移行可能です。カスタムCUDAカーネルを多用している場合は、移行コストが高くなります。
Q. なぜIntelはGPU事業と別にGaudiを開発しているのですか?
歴史的経緯とアーキテクチャの違いによります。Gaudiは買収したHabana Labsの技術に基づき、AI専用に設計されています。Intel GPUはグラフィックス処理が主目的で、AI対応は後付けです。将来的にはFalcon Shoresで統合される計画です。
まとめ

Intel Gaudiシリーズは、NVIDIA独占のAI半導体市場に挑戦する重要な製品です。Gaudi 3はH100に匹敵する性能を40〜60%安価で提供し、内蔵ネットワークによるTCO削減も魅力です。
CUDAエコシステムとの互換性課題は残りますが、PyTorch/Hugging Face対応の充実により、実用性は向上しています。NVIDIA一強からの分散を図る企業にとって、AMDのMI300Xと並ぶ有力な選択肢です。
https://ainow.jp/ai-semiconductor-guide/

https://ainow.jp/amd-mi300-guide/
 OpenAI
OpenAI Google
Google ChatGPT
ChatGPT Bard
Bard Stable Diffusion
Stable Diffusion Midjourney
Midjourney
