


AMD MI300は、NVIDIAに対抗するAMDの最新AIアクセラレータです。192GBの大容量HBM3メモリを搭載し、大規模言語モデルの学習・推論に最適化。本記事では、MI300X・MI300Aのスペック、NVIDIA H100との比較、価格、導入事例を徹底解説します。
AMD MI300とは
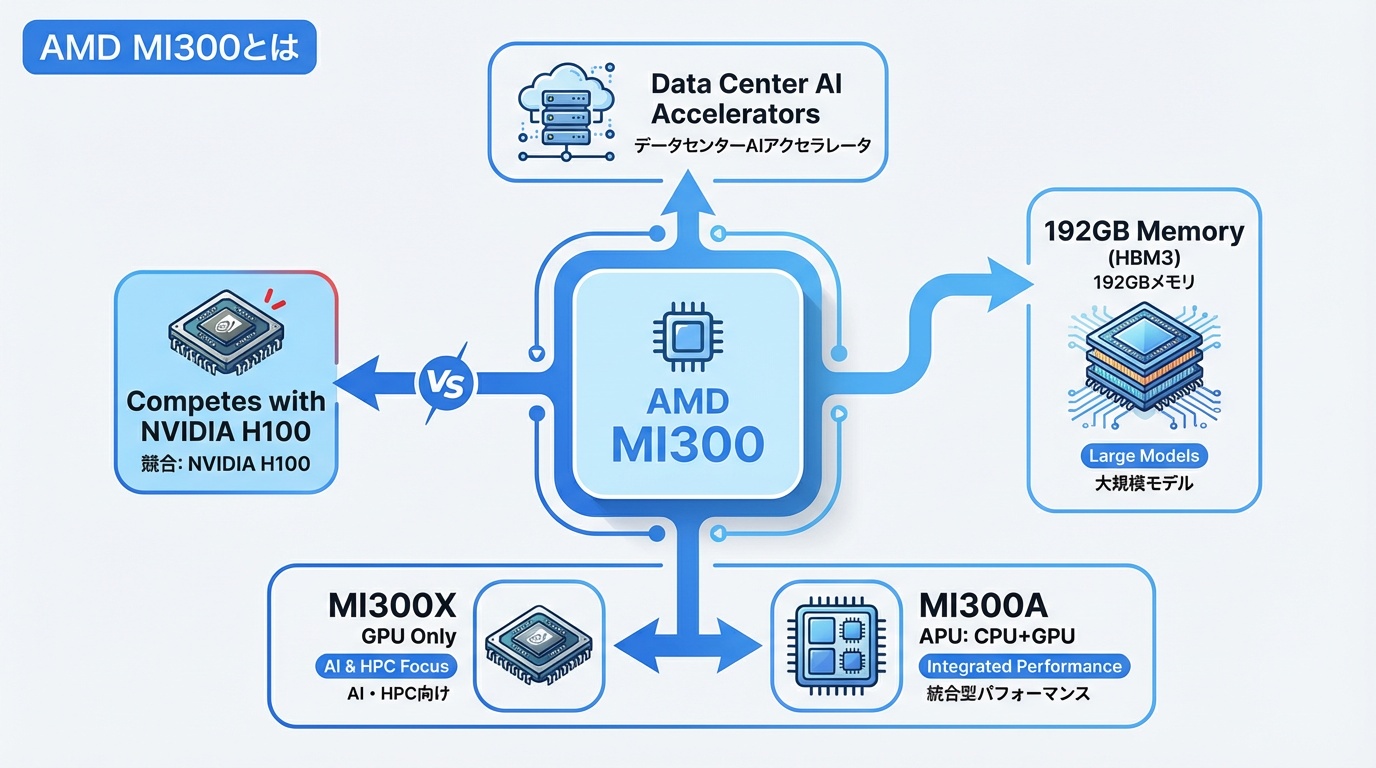
AMD MI300は、2023年12月に発表されたAMDのデータセンター向けAIアクセラレータです。NVIDIA H100の独占状態に風穴を開ける製品として、Microsoft、Meta、Oracleなど大手テック企業が採用を表明し、AI半導体市場の競争を加速させています。
MI300シリーズの位置づけ
AMDはCPU(Ryzen、EPYC)とGPU(Radeon)の両方を手がける世界唯一の半導体メーカーです。MI300シリーズは、このCPUとGPUの技術を統合し、AIワークロードに最適化した製品ラインです。
- MI300X:GPU単体製品。大規模モデルの学習・推論に特化
- MI300A:CPU(EPYC)とGPU(CDNA 3)を統合したAPU。HPC向け
開発の背景
NVIDIA H100の供給不足と高騰が続く中、大手クラウドベンダーは代替製品を求めていました。AMDはこの市場機会を捉え、MI300シリーズを投入。特に192GBという大容量メモリは、700億パラメータ超の大規模モデルを1台で処理できる点で差別化を図っています。
MI300Xのスペック詳細
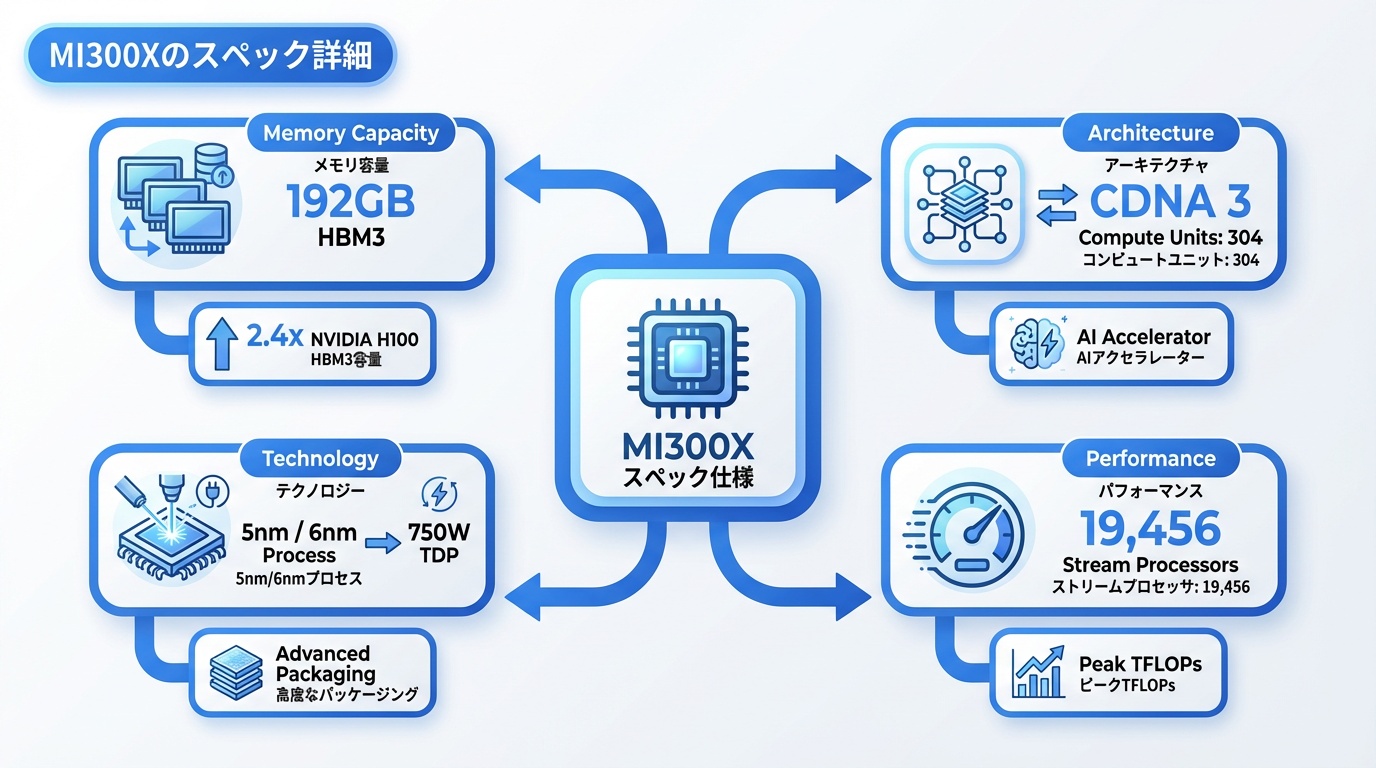
MI300Xは、AI推論・学習に特化したGPUアクセラレータです。主要スペックを解説します。
基本仕様
- アーキテクチャ:CDNA 3(第3世代)
- 演算ユニット:304 Compute Units(19,456ストリームプロセッサ)
- トランジスタ数:1,530億個
- 製造プロセス:TSMC 5nm / 6nm(チップレット構成)
- TDP:750W
メモリ構成
- HBM3メモリ:192GB(業界最大)
- メモリ帯域:5.3TB/s
- メモリスタック:8スタック(各24GB)
192GBのメモリ容量は、NVIDIA H100(80GB)の2.4倍。Llama 2 70Bのような大規模モデルを、メモリ分割なしで1台のGPUに収容できます。
AI演算性能
- FP16:1,307 TFLOPS
- FP8:2,614 TFLOPS
- INT8:2,614 TOPS
- スパース演算(FP8):5,200+ TFLOPS
MI300AのスペックとHPC向け特徴
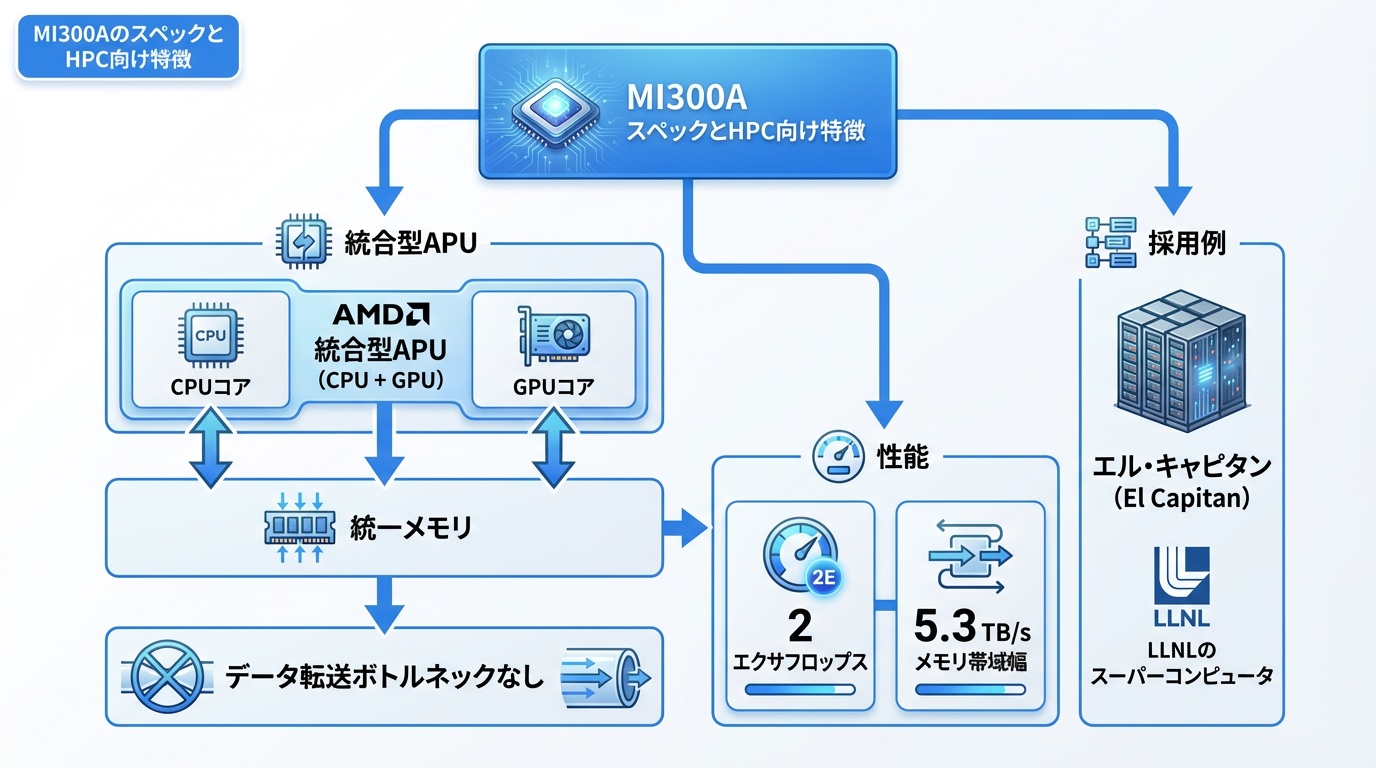
MI300Aは、CPUとGPUを1パッケージに統合したAPU(Accelerated Processing Unit)です。
統合アーキテクチャ
- CPU:Zen 4コア × 24(EPYC相当)
- GPU:CDNA 3 × 228 CU
- メモリ:128GB HBM3(統合メモリ)
- メモリ帯域:5.3TB/s
統合メモリの利点
従来のCPU+GPU構成では、CPUメモリとGPUメモリ間のデータ転送がボトルネックになっていました。MI300Aは統合メモリにより、このオーバーヘッドを解消。科学シミュレーションなど、CPUとGPUを頻繁に行き来するワークロードで大幅な性能向上が期待できます。
採用事例
ローレンス・リバモア国立研究所の次世代スーパーコンピュータ「El Capitan」に採用。2エクサフロップス超の演算能力を実現し、核融合シミュレーションなどに活用されます。
NVIDIA H100との比較
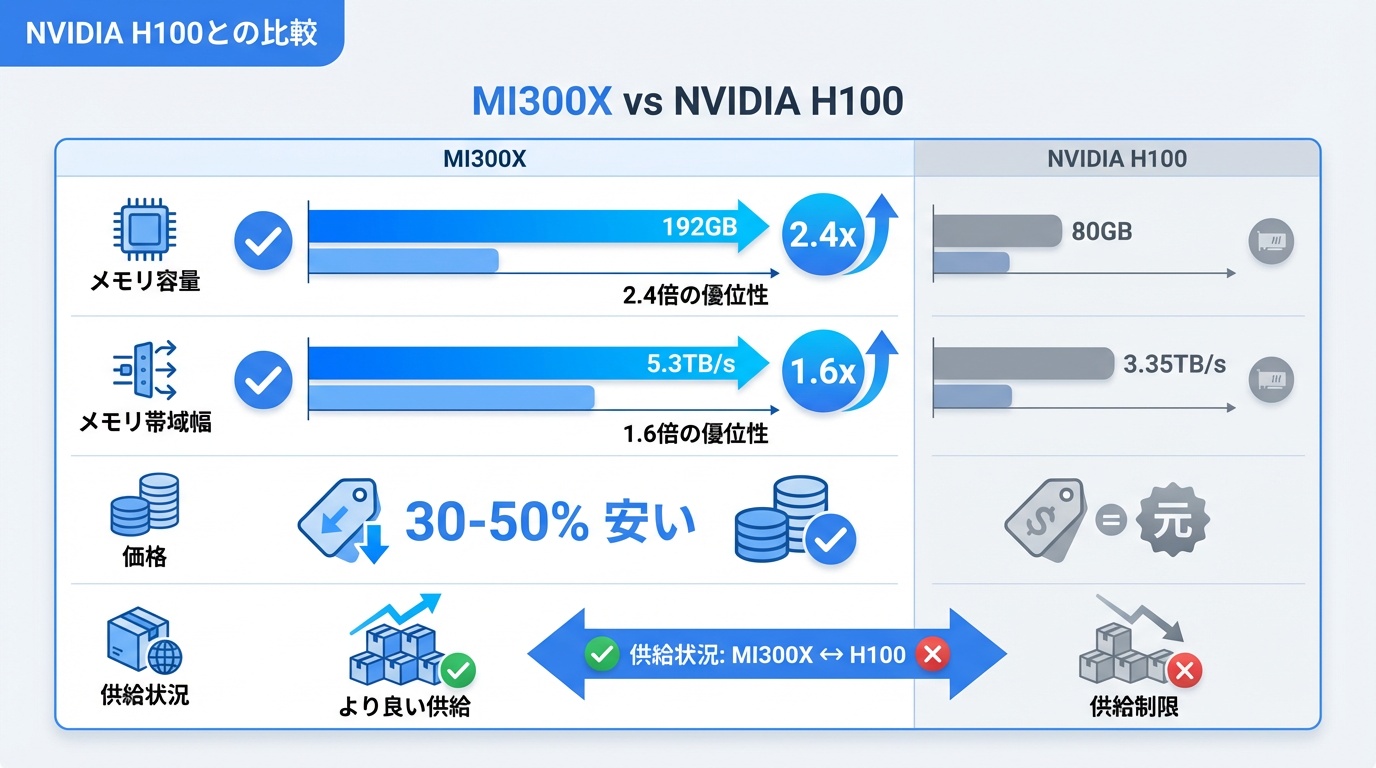
MI300XとNVIDIA H100の主要スペックを比較します。
| 項目 | AMD MI300X | NVIDIA H100 SXM |
|---|---|---|
| メモリ容量 | 192GB HBM3 | 80GB HBM3 |
| メモリ帯域 | 5.3TB/s | 3.35TB/s |
| FP16性能 | 1,307 TFLOPS | 989 TFLOPS |
| FP8性能 | 2,614 TFLOPS | 1,979 TFLOPS |
| TDP | 750W | 700W |
| 製造プロセス | 5nm/6nm | 4nm |
| 価格(推定) | $15,000〜20,000 | $25,000〜40,000 |
| ソフトウェア | ROCm | CUDA |
MI300Xの優位点
- メモリ容量:192GB vs 80GBで2.4倍。大規模モデルに有利
- メモリ帯域:5.3TB/s vs 3.35TB/sで1.6倍。推論スループット向上
- 価格:推定30〜50%安価。TCO(総所有コスト)で優位
- 入手性:H100ほど供給不足が深刻でない
NVIDIA H100の優位点
- ソフトウェアエコシステム:CUDAの圧倒的なライブラリ・ツール群
- Transformer Engine:FP8学習の自動最適化
- NVLink:マルチGPUスケーリングの成熟度
- 実績:ChatGPT、Claude等の主要LLMで使用実績
ROCmソフトウェアエコシステム
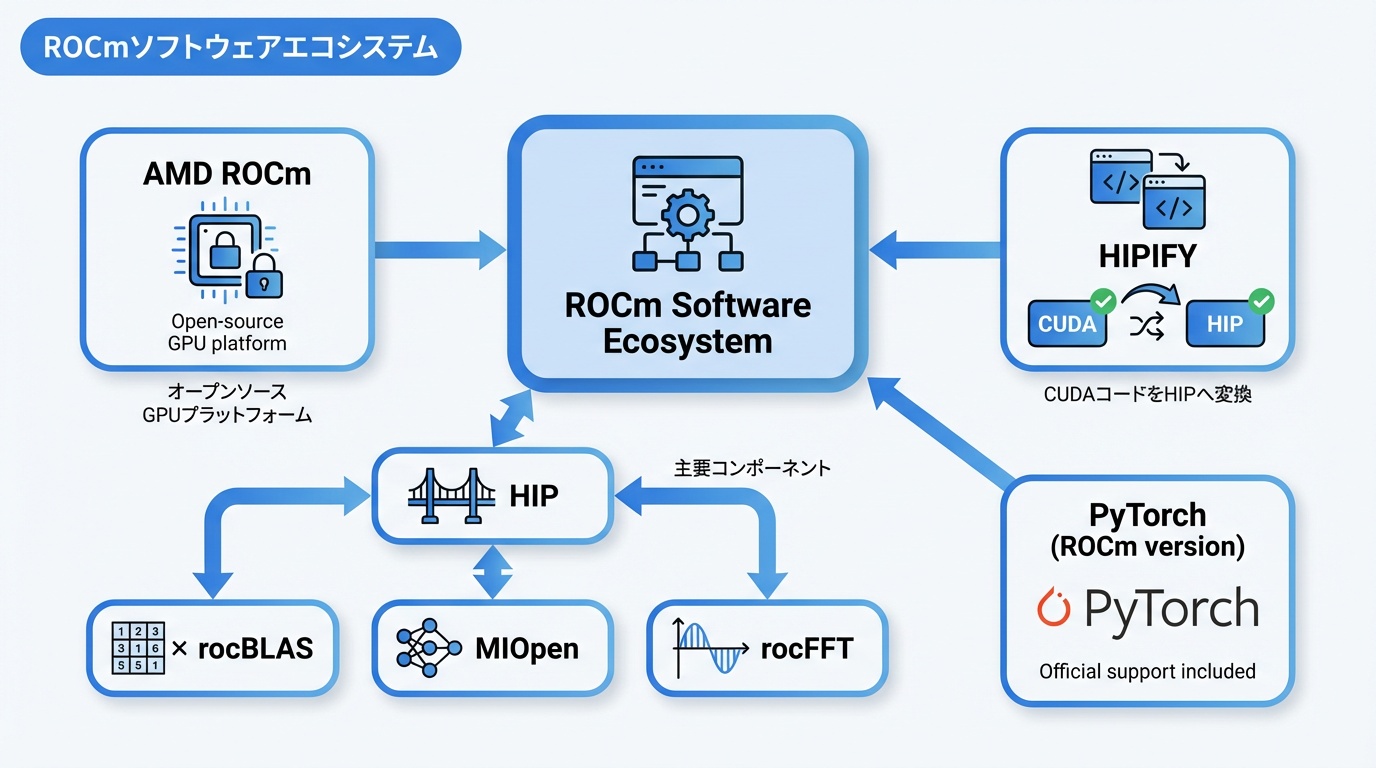
MI300シリーズの価値を最大化するには、ROCm(Radeon Open Compute)エコシステムの理解が重要です。
ROCmとは
ROCmは、AMDが開発するオープンソースのGPUコンピューティングプラットフォームです。NVIDIAのCUDAに対抗する位置づけで、以下のコンポーネントで構成されています。
- HIP:CUDAライクなプログラミングモデル
- rocBLAS:線形代数ライブラリ
- MIOpen:ディープラーニングプリミティブ
- rocFFT:高速フーリエ変換
主要フレームワーク対応
- PyTorch:公式サポート(ROCm版)
- TensorFlow:公式サポート
- JAX:実験的サポート
- ONNX Runtime:サポート
CUDAコードの移行
AMDは「HIPIFY」ツールを提供し、CUDAコードをHIP(AMD GPU用)に自動変換できます。多くのケースで90%以上のコードが自動変換可能ですが、高度なCUDA機能を使用している場合は手動調整が必要です。
主要クラウドでの提供状況
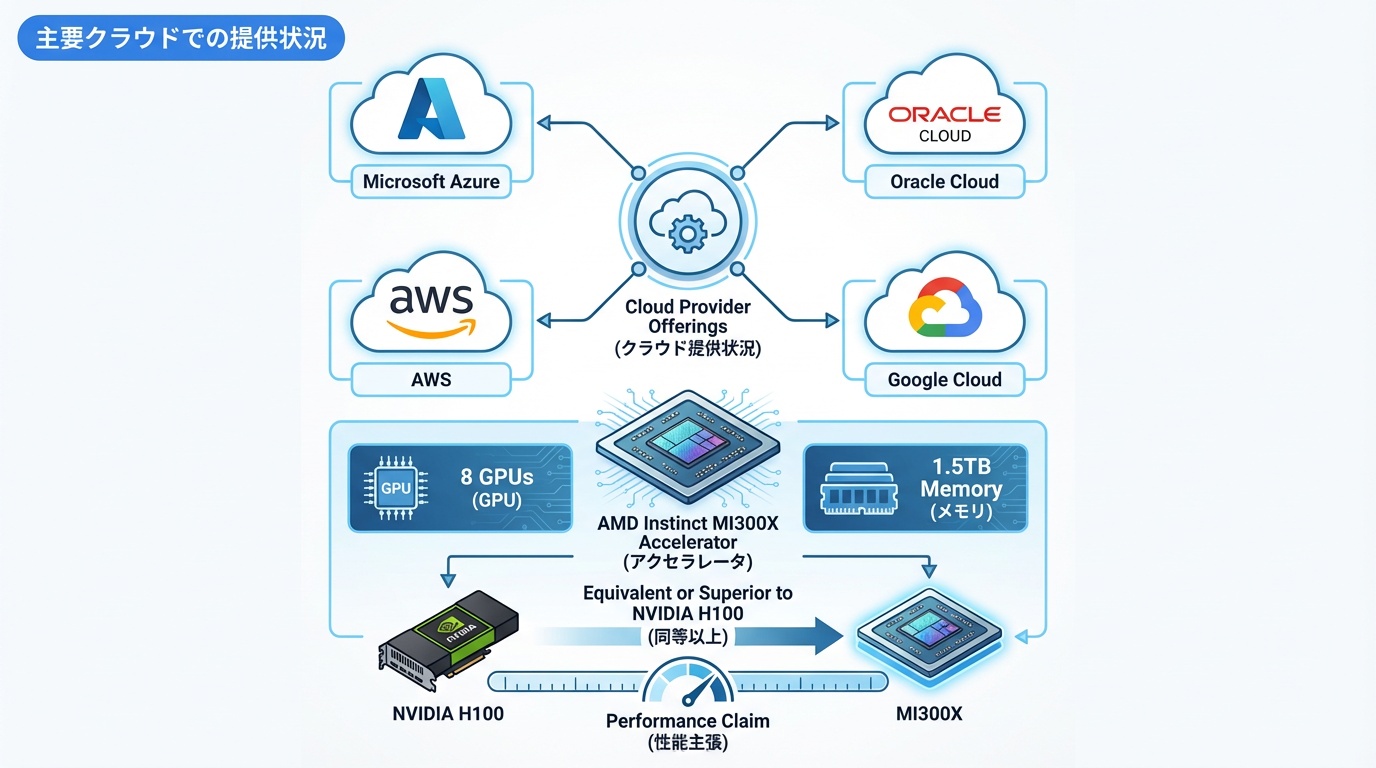
MI300Xは主要クラウドプロバイダーで提供が開始されています。
Microsoft Azure
Azure ND MI300X v5シリーズとして提供。8基のMI300Xを搭載し、1.5TBのGPUメモリを実現。OpenAIの一部ワークロードでも検証が進んでいます。
Oracle Cloud
OCI Compute E5インスタンスとして提供。ベアメタルで8基のMI300Xを利用可能。Oracleは「NVIDIA H100と同等以上の推論性能」と発表しています。
AWS
2025年後半にEC2インスタンスとして提供予定。現時点では未提供ですが、AWSとAMDの提携強化が進んでいます。
Google Cloud
2025年中の提供を計画中。TPUとの棲み分けを模索しています。
導入事例と採用企業
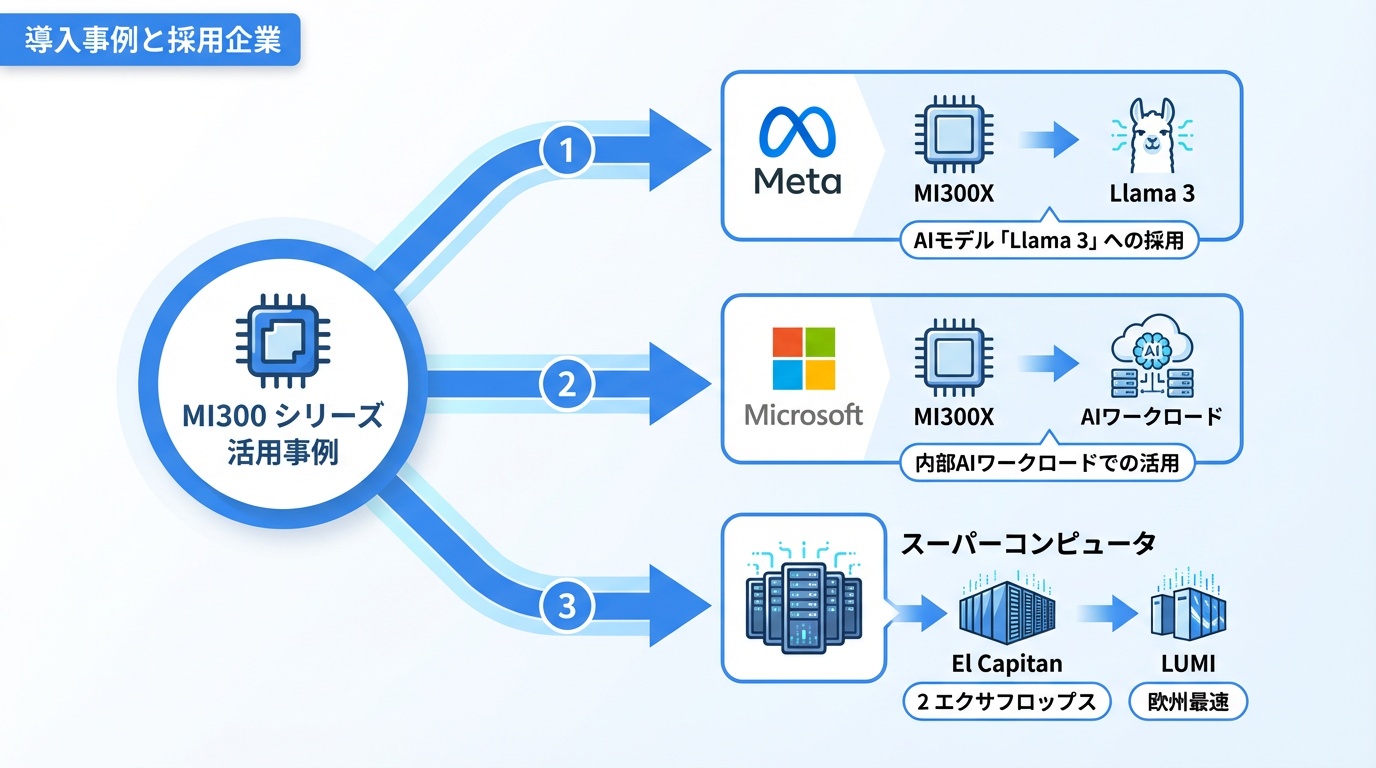
MI300シリーズの主要な導入事例を紹介します。
Meta(Facebook)
Metaは2024年、大規模言語モデル「Llama 3」の学習にMI300Xを採用すると発表。従来のNVIDIA GPU依存からの分散を進めています。Metaは「推論ワークロードでMI300Xのメモリ容量が大きなアドバンテージ」と評価しています。
Microsoft
Azure経由での提供に加え、Microsoft社内のAIワークロードでもMI300Xを検証中。Copilotの一部推論処理での活用が報じられています。
スーパーコンピュータ
- El Capitan(米国):MI300A採用、2エクサフロップス超
- LUMI(フィンランド):MI250X採用、欧州最速
価格と入手方法
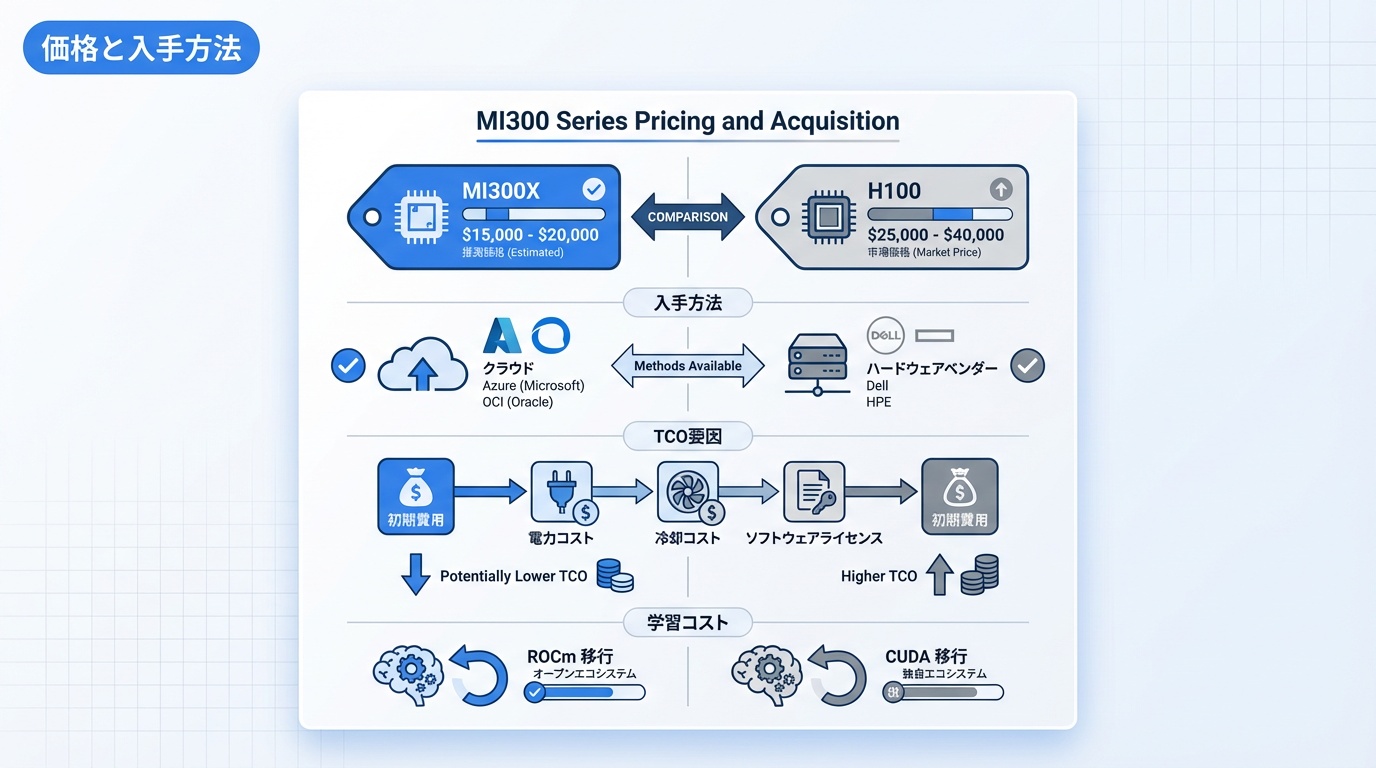
MI300シリーズの価格と入手方法を解説します。
価格帯
- MI300X:推定$15,000〜20,000/台
- MI300A:推定$12,000〜15,000/台
NVIDIA H100($25,000〜40,000)と比較して30〜50%安価とされています。ただし、市場価格は需給バランスにより変動します。
入手方法
- クラウド:Azure、OCI等で時間課金利用(最も手軽)
- サーバーベンダー:Dell、HPE、Supermicro等から搭載サーバーを購入
- AMD直販:大口顧客向け
TCO(総所有コスト)比較
初期費用だけでなく、電力コスト、冷却コスト、ソフトウェアライセンスを含めたTCOで評価することが重要です。MI300Xは初期費用で優位ですが、ROCmの学習コストやCUDA移行コストを考慮する必要があります。
今後のロードマップ
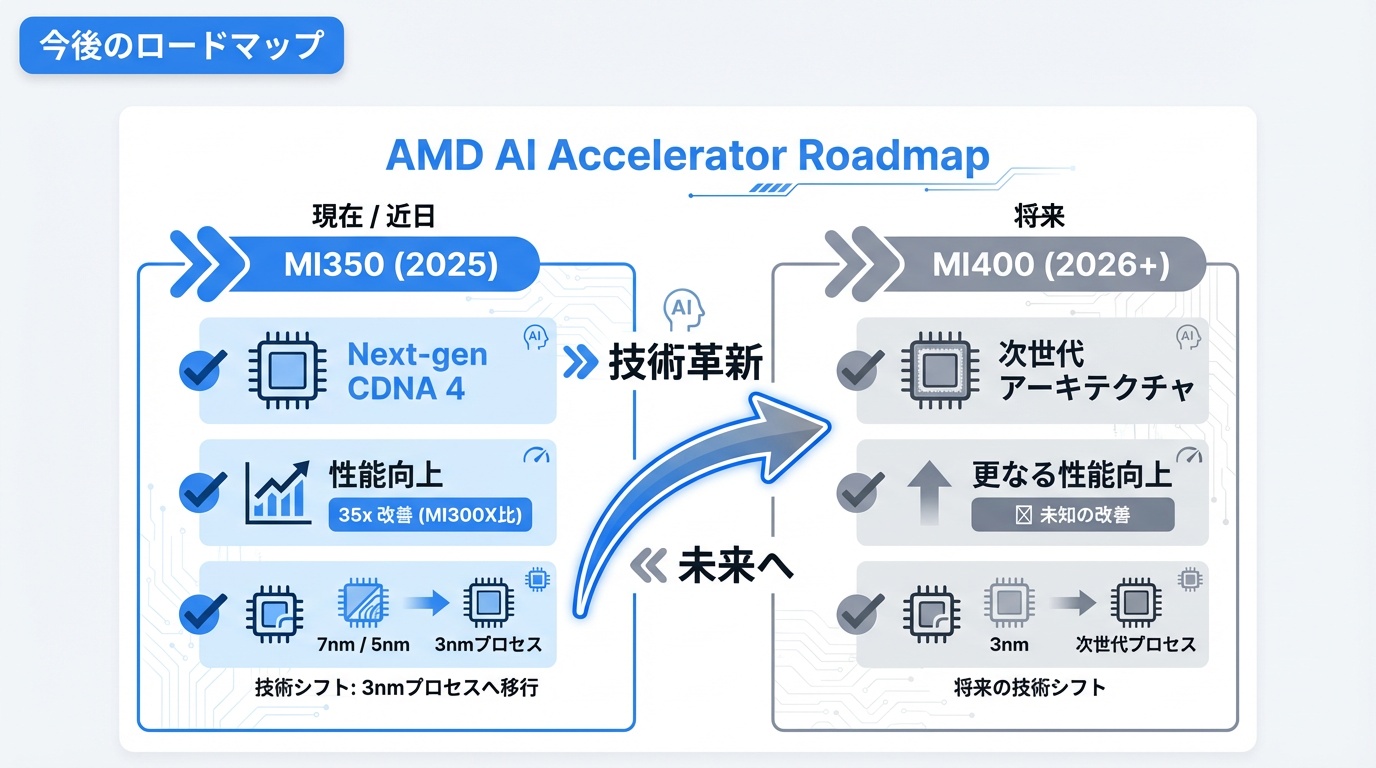
AMDのAIアクセラレータの今後の展開を解説します。
MI350シリーズ(2025年予定)
次世代CDNA 4アーキテクチャを採用。MI300X比で35倍のAI推論性能向上を目標としています。3nm プロセスへの移行も予定されています。
MI400シリーズ(2026年以降)
さらなる性能向上とエネルギー効率の改善を計画。NVIDIAのBlackwell世代に対抗する製品となる見込みです。
ソフトウェア強化
ROCmの機能拡充、PyTorch/TensorFlowとの統合強化、CUDA互換性の向上が継続的に進められています。
よくある質問
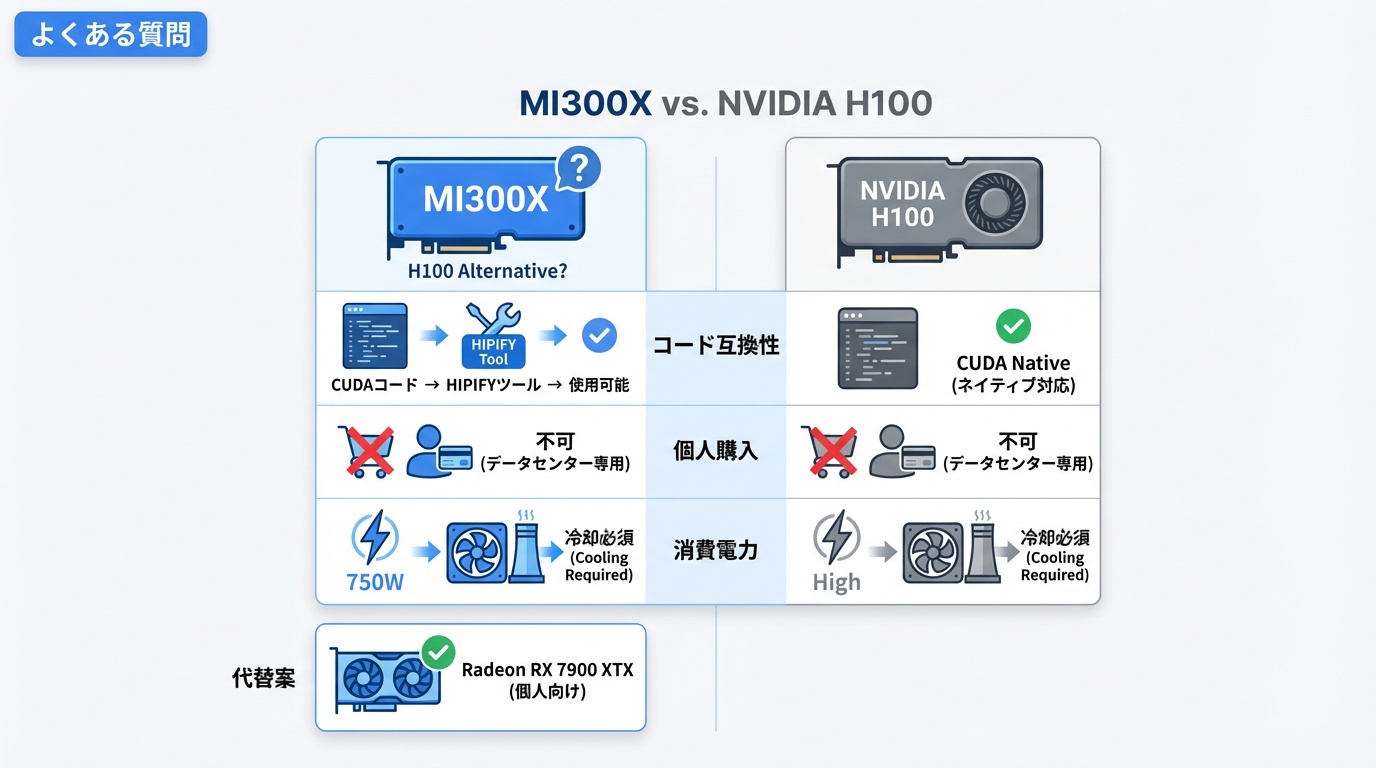
Q. MI300XはNVIDIA H100の代替になりますか?
ワークロードによります。推論用途、特に大規模モデルではメモリ容量の優位性から有力な代替となります。一方、学習用途ではCUDAエコシステムの成熟度からH100が依然有利なケースが多いです。
Q. CUDAで書かれたコードはMI300Xで動きますか?
HIPIFYツールで変換が必要です。多くのコードは自動変換可能ですが、CUDA固有の機能を使用している場合は手動修正が必要です。PyTorch、TensorFlowを使用している場合は、ROCm版に切り替えるだけで動作します。
Q. 個人で購入できますか?
MI300Xはデータセンター向け製品であり、個人向け販売は行われていません。個人でAMD GPUを使用したい場合は、Radeon RX 7900 XTX(ROCm対応)が選択肢です。クラウドでMI300Xを時間課金で利用することも可能です。
Q. 消費電力が750Wと高いですが、冷却は大丈夫ですか?
MI300Xはデータセンター向け製品であり、液冷または高性能空冷が前提です。一般的なオフィス環境での運用は想定されていません。クラウド利用であれば、冷却は提供者側で対応されます。
Q. MI300XとMI300Aはどちらを選ぶべきですか?
用途によります。純粋なAIワークロード(学習・推論)ならMI300X、科学シミュレーションなどCPU-GPU連携が重要なHPCワークロードならMI300Aが適しています。
まとめ
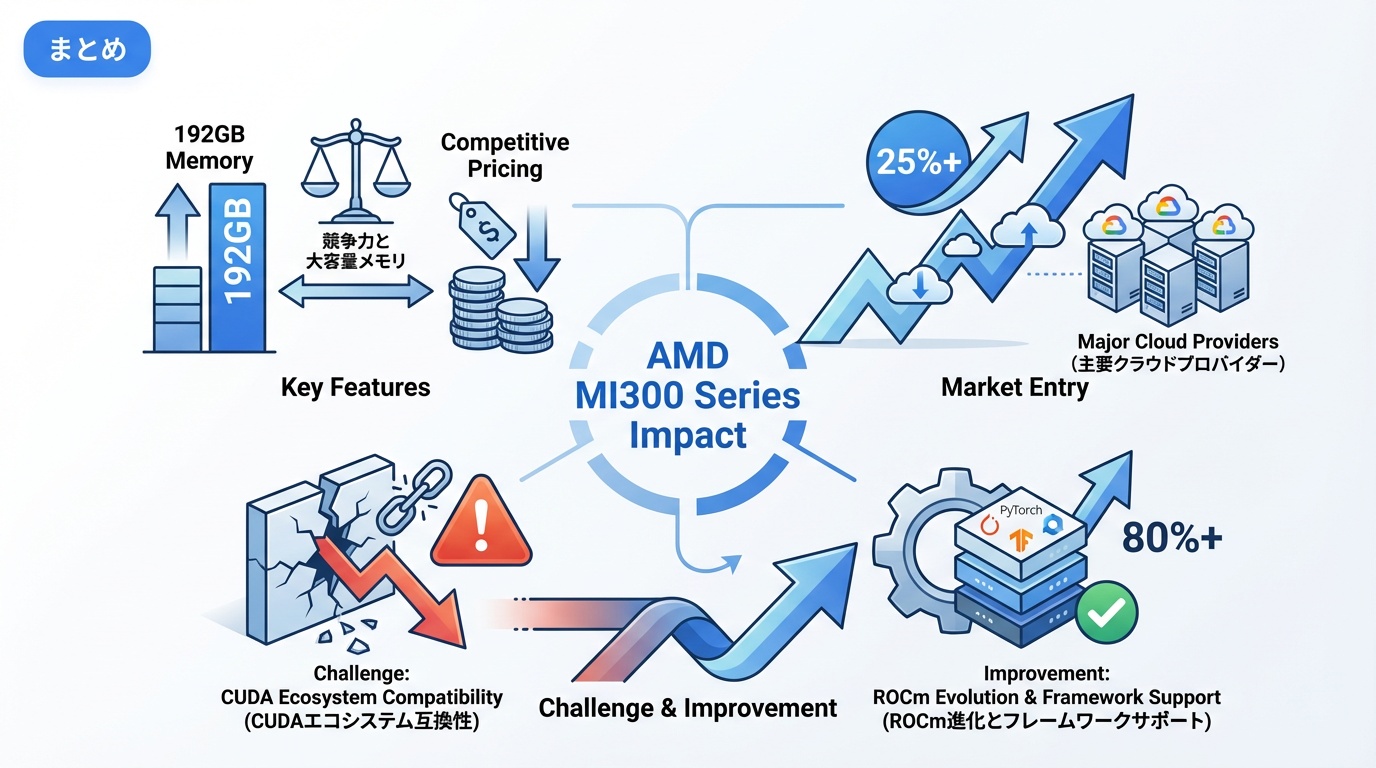
AMD MI300シリーズは、NVIDIA独占のAI半導体市場に風穴を開ける重要な製品です。192GBの大容量メモリ、競争力のある価格、主要クラウドでの提供開始により、AI開発の選択肢が広がりました。
CUDAエコシステムとの互換性課題は残りますが、ROCmの進化とフレームワークサポートの拡充により、実用性は着実に向上しています。NVIDIA一強からの脱却を目指す企業にとって、MI300Xは検討に値する選択肢です。
https://ainow.jp/ai-semiconductor-guide/

https://ainow.jp/edge-ai-guide/
 OpenAI
OpenAI Google
Google ChatGPT
ChatGPT Bard
Bard Stable Diffusion
Stable Diffusion Midjourney
Midjourney
