


強化学習(Reinforcement Learning)は、ロボットに複雑なタスクを自律的に学習させる革新的な技術です。シミュレーションで学習し実機に転用する「Sim-to-Real」技術の進化により、産業応用が加速しています。本記事では、強化学習×ロボットの基礎から最新研究、実用化事例まで徹底解説します。
強化学習とは?ロボット制御への適用
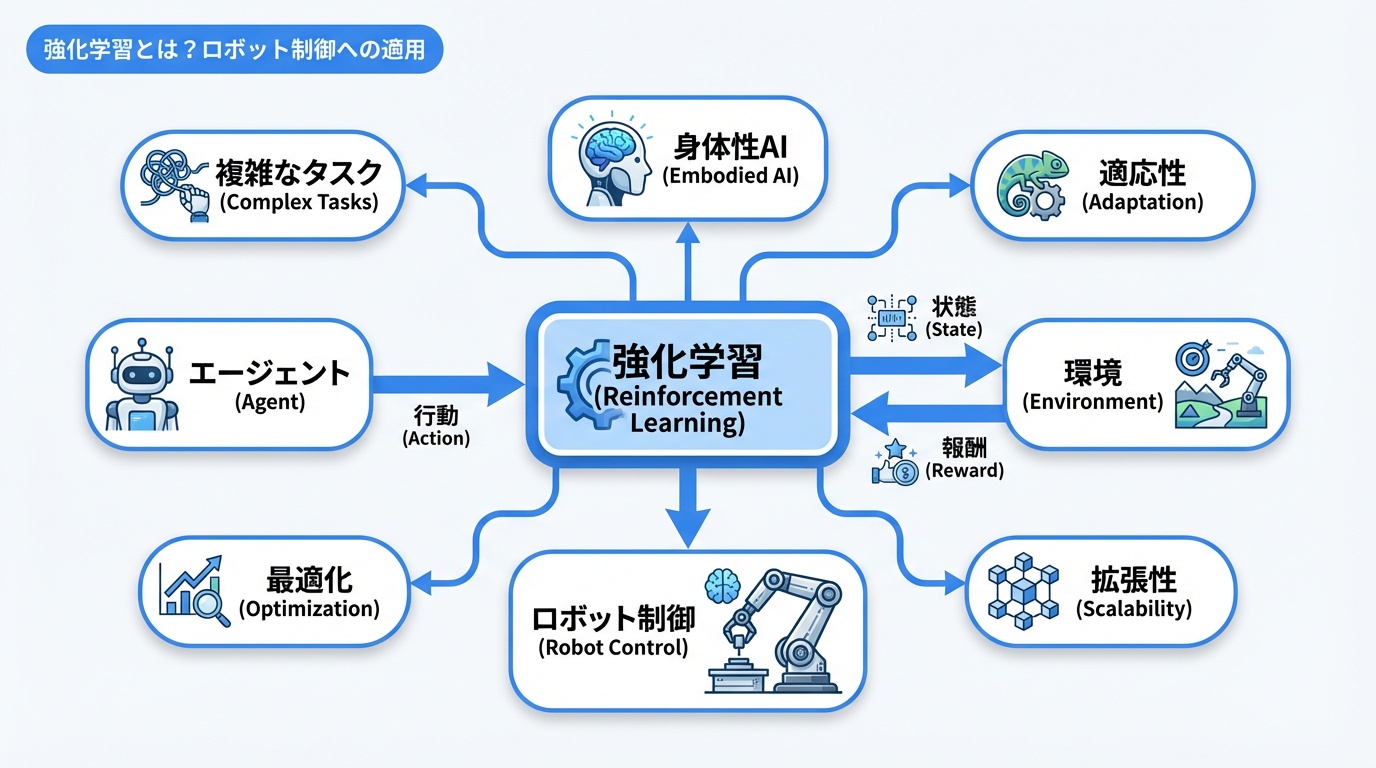
強化学習は、エージェント(ロボット)が環境との相互作用を通じて、報酬を最大化する行動を学習する機械学習手法です。
強化学習の基本概念
| 用語 | ロボットでの意味 | 例 |
|---|---|---|
| エージェント | 学習するロボット | マニピュレータ、移動ロボット |
| 環境 | ロボットが動作する世界 | 工場、倉庫、シミュレータ |
| 状態(State) | ロボットの現在の状況 | 関節角度、カメラ画像 |
| 行動(Action) | ロボットが取る動作 | モーター制御、移動方向 |
| 報酬(Reward) | 行動の良し悪し | タスク成功+1、失敗-1 |
| 方策(Policy) | 状態から行動への写像 | ニューラルネットワーク |
なぜロボットに強化学習が有効か
- 複雑なタスク:従来のプログラミングでは記述困難な動作を学習
- 環境適応:変化する環境に柔軟に対応
- 最適化:人間が設計するより効率的な動作を発見
- スケーラビリティ:一度学習すれば多数のロボットに展開
Embodied AIの中核技術として強化学習は重要な位置を占めています。
ロボット強化学習の主要アルゴリズム
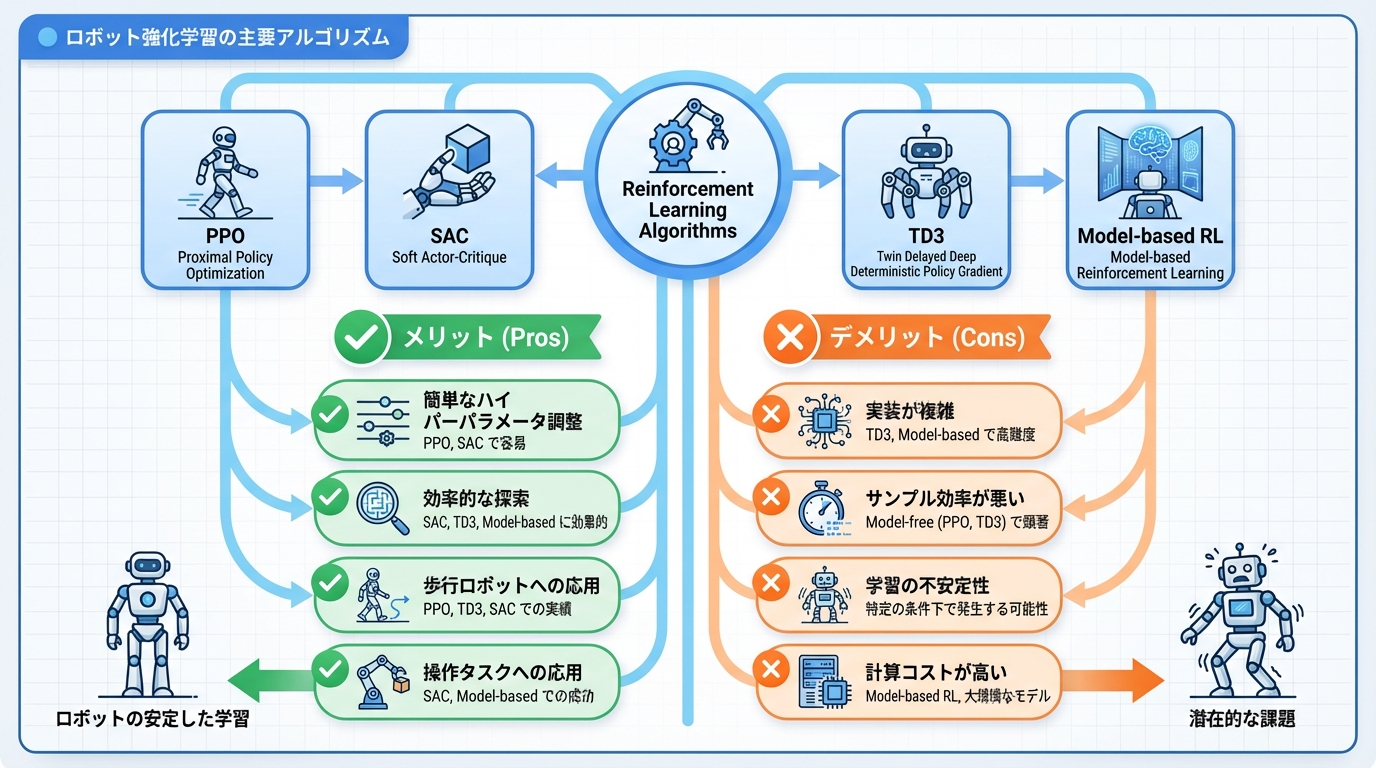
ロボット制御でよく使われる強化学習アルゴリズムを解説します。
1. PPO(Proximal Policy Optimization)
安定した学習が可能で、ロボット分野で最も広く使われています。
- 特徴:方策の更新幅を制限し安定性を確保
- 利点:ハイパーパラメータ調整が容易
- 適用例:歩行ロボット、マニピュレーション
2. SAC(Soft Actor-Critic)
探索と活用のバランスに優れた手法です。
- 特徴:エントロピー最大化による効率的な探索
- 利点:サンプル効率が良い
- 適用例:連続制御、精密操作
3. TD3(Twin Delayed DDPG)
連続行動空間での安定した学習を実現します。
- 特徴:過大評価バイアスを軽減
- 利点:連続制御に適している
- 適用例:アーム制御、ドローン
4. Model-based RL
環境のモデルを学習して効率的に計画を立てます。
- 特徴:環境ダイナミクスをモデル化
- 利点:少ないサンプルで学習可能
- 適用例:長期的な計画が必要なタスク
Sim-to-Real:シミュレーションから実機へ

Sim-to-Realは、シミュレーション環境で学習した方策を実機ロボットに転用する技術です。ロボット強化学習の実用化に不可欠な技術として急速に発展しています。
Sim-to-Realが必要な理由
- 安全性:実機での試行錯誤は危険・コストがかかる
- 効率性:シミュレーションは実時間の数百倍で実行可能
- 再現性:様々な条件を簡単にテスト可能
Reality Gap(現実とのギャップ)の克服
シミュレーションと実環境の差異を「Reality Gap」と呼びます。これを克服する技術が重要です。
| 技術 | 概要 | 効果 |
|---|---|---|
| ドメインランダマイゼーション | 物理パラメータをランダム化 | 汎化性能向上 |
| ドメイン適応 | シミュと実機の分布を近づける | 転移精度向上 |
| System Identification | 実機パラメータを精密推定 | シミュ精度向上 |
| Residual Learning | シミュと実機の差分を学習 | 補正精度向上 |
主要シミュレータ
| シミュレータ | 開発元 | 特徴 |
|---|---|---|
| Isaac Sim | NVIDIA | GPU並列、フォトリアル |
| MuJoCo | DeepMind | 高速物理演算、研究用途 |
| PyBullet | OSS | 軽量、教育向け |
| Gazebo | Open Robotics | ROS統合、実用向け |
| Unity ML-Agents | Unity | ゲームエンジン活用 |
NVIDIA GR00TはIsaac Simを活用した代表的なプラットフォームです。
強化学習ロボットの応用事例
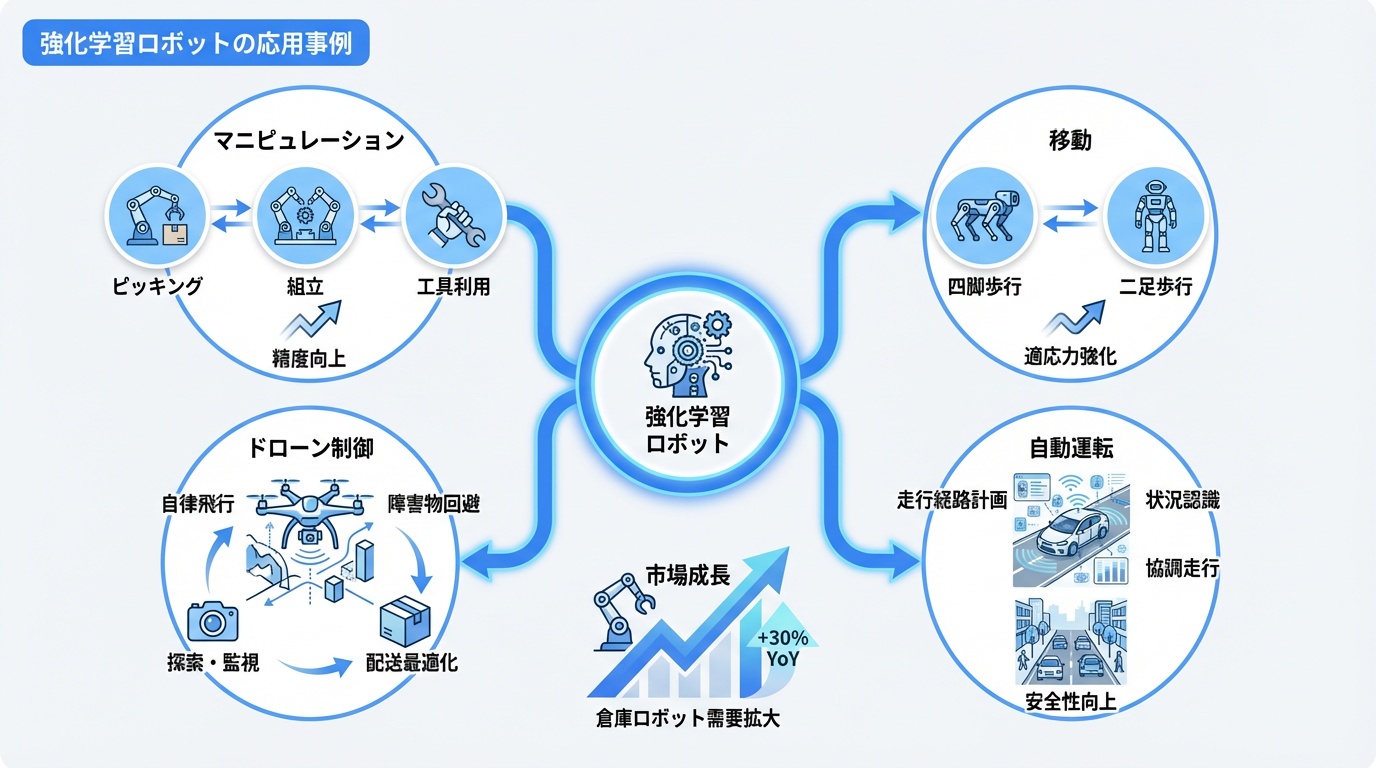
強化学習によるロボット制御は様々な分野で実用化されています。
1. マニピュレーション(物体操作)
- ピッキング:多様な物体を把持して移動
- 組立作業:精密な部品の挿入・嵌合
- 道具使用:ハンマー、スパナなどの道具操作
倉庫ロボットでの活用が進んでいます。
2. 移動・歩行
- 四足歩行:不整地を安定して歩行
- 二足歩行:人間のような動的バランス
- 階段昇降:段差への適応
ヒューマノイドロボットの歩行制御に活用されています。
3. ドローン制御
- アクロバット飛行:人間を超える機動性
- 障害物回避:高速環境での自律飛行
- 協調飛行:複数ドローンの編隊制御
4. 自動運転
- 端末制御:ステアリング・アクセルの精密制御
- 意思決定:車線変更・合流の判断
- 緊急回避:予測不能な状況への対応
自動運転技術への応用が研究されています。
最新研究動向(2026年)
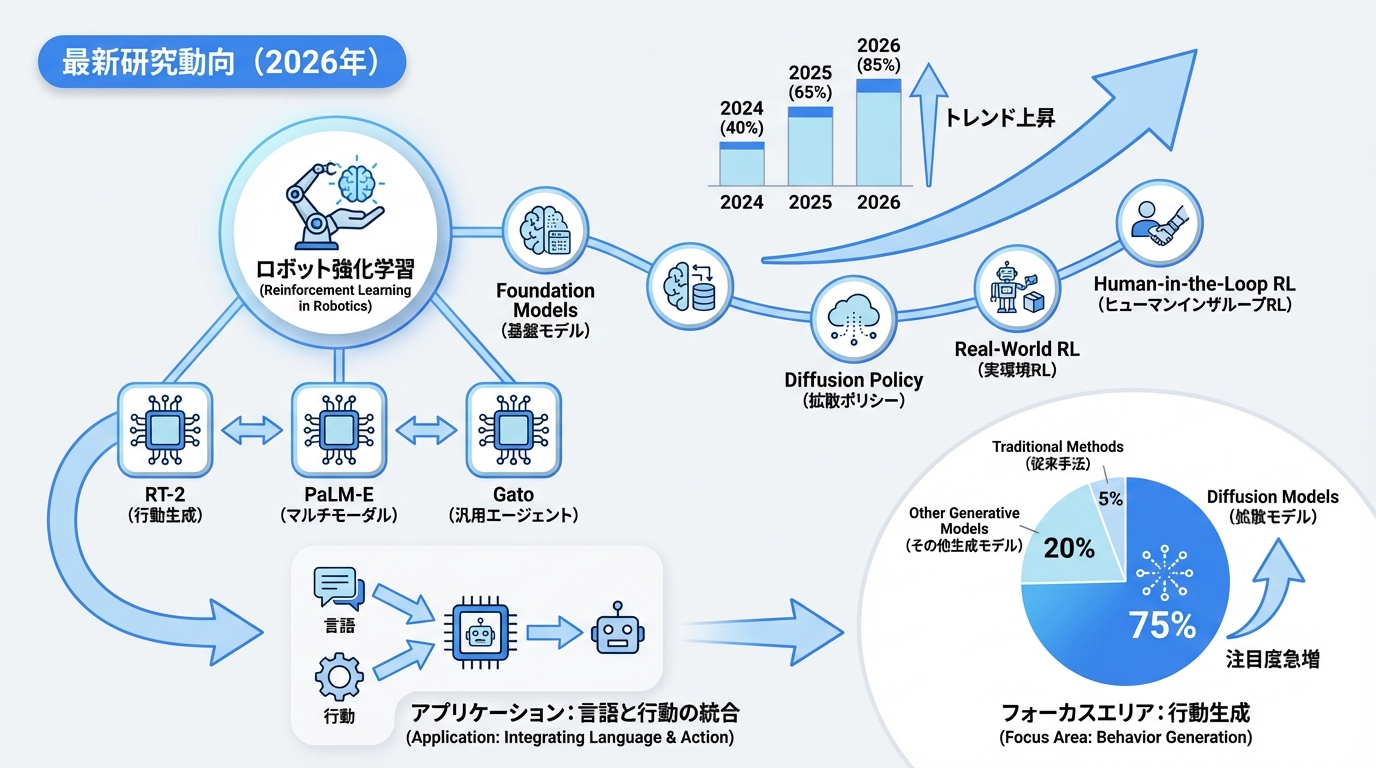
強化学習×ロボットの最新研究トレンドを紹介します。
1. Foundation Models for Robotics
大規模言語モデルや視覚モデルをロボット制御に活用する研究が活発です。
- RT-2(Google):言語と行動を統合したモデル
- PaLM-E(Google):マルチモーダル具現化AI
- Gato(DeepMind):汎用エージェントモデル
2. Diffusion Policy
拡散モデルを用いた行動生成が注目されています。
- 複雑な行動分布を表現可能
- 少数デモンストレーションからの学習
- マルチモーダルな行動生成
3. Real-World RL
シミュレーションを介さず、実機で直接学習する研究も進んでいます。
- オフライン強化学習の活用
- 安全制約付き学習
- 効率的な実機データ収集
4. Human-in-the-Loop RL
人間のフィードバックを学習に取り入れる手法です。
- 報酬設計の自動化
- 人間の好みに沿った行動学習
- 安全な探索の実現
強化学習ロボット開発の実践ガイド
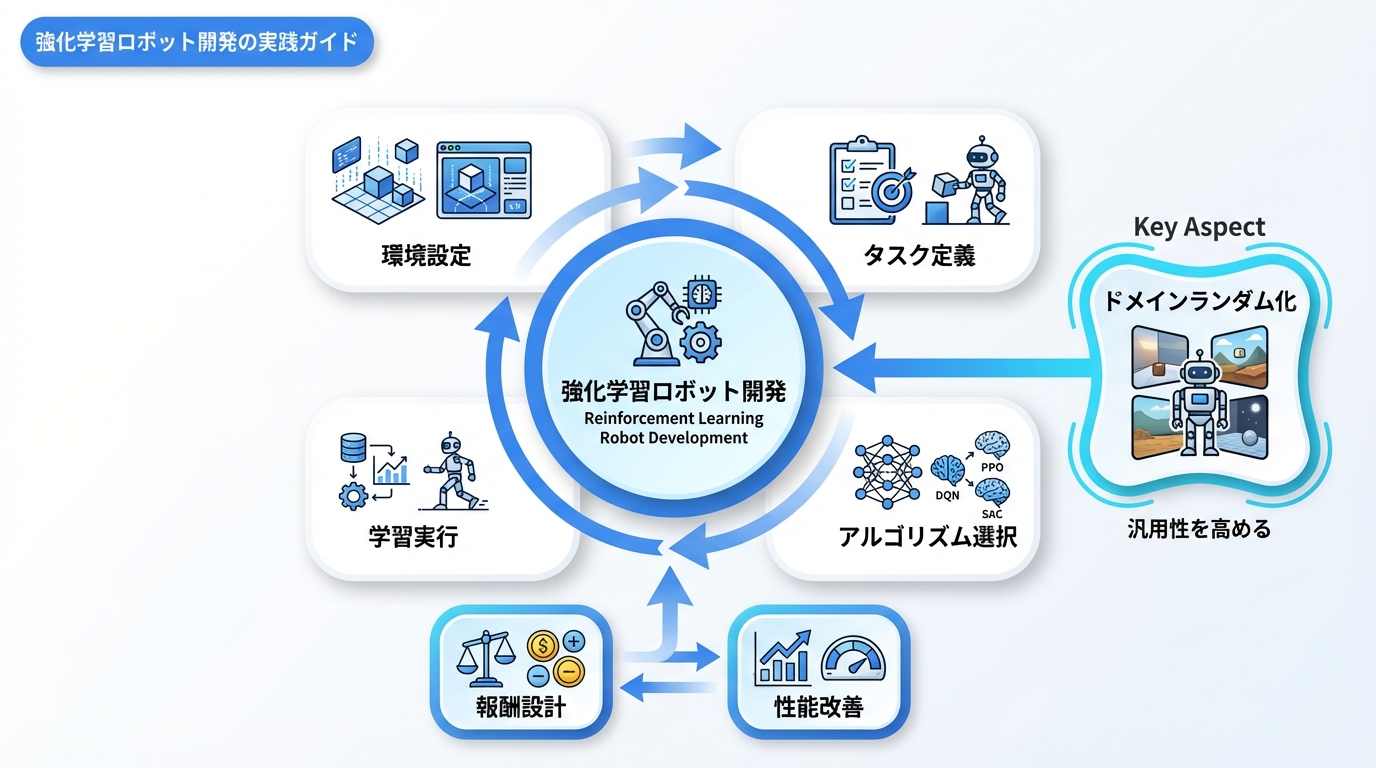
強化学習でロボット制御を始めるための実践的なガイドです。
開発環境の構築
# 基本ライブラリ
pip install gymnasium stable-baselines3 pybullet
# NVIDIA Isaac(推奨)
# 要:NVIDIA GPU + Ubuntu
# https://developer.nvidia.com/isaac-sim学習パイプライン
- タスク定義:目標、状態空間、行動空間、報酬を設計
- シミュ環境構築:物理パラメータ、センサーを設定
- アルゴリズム選択:タスク特性に応じて選定(PPO/SAC等)
- 学習実行:ハイパーパラメータ調整しながら学習
- ドメインランダマイゼーション:汎化性能を向上
- Sim-to-Real転移:実機で検証・微調整
報酬設計のベストプラクティス
- スパース報酬:タスク完了時のみ報酬(難易度高)
- デンス報酬:中間的な達成度に報酬(設計が重要)
- 報酬シェーピング:ゴールへの距離に応じた報酬
- カリキュラム学習:簡単なタスクから徐々に難易度上昇
まとめ|強化学習×ロボットの未来
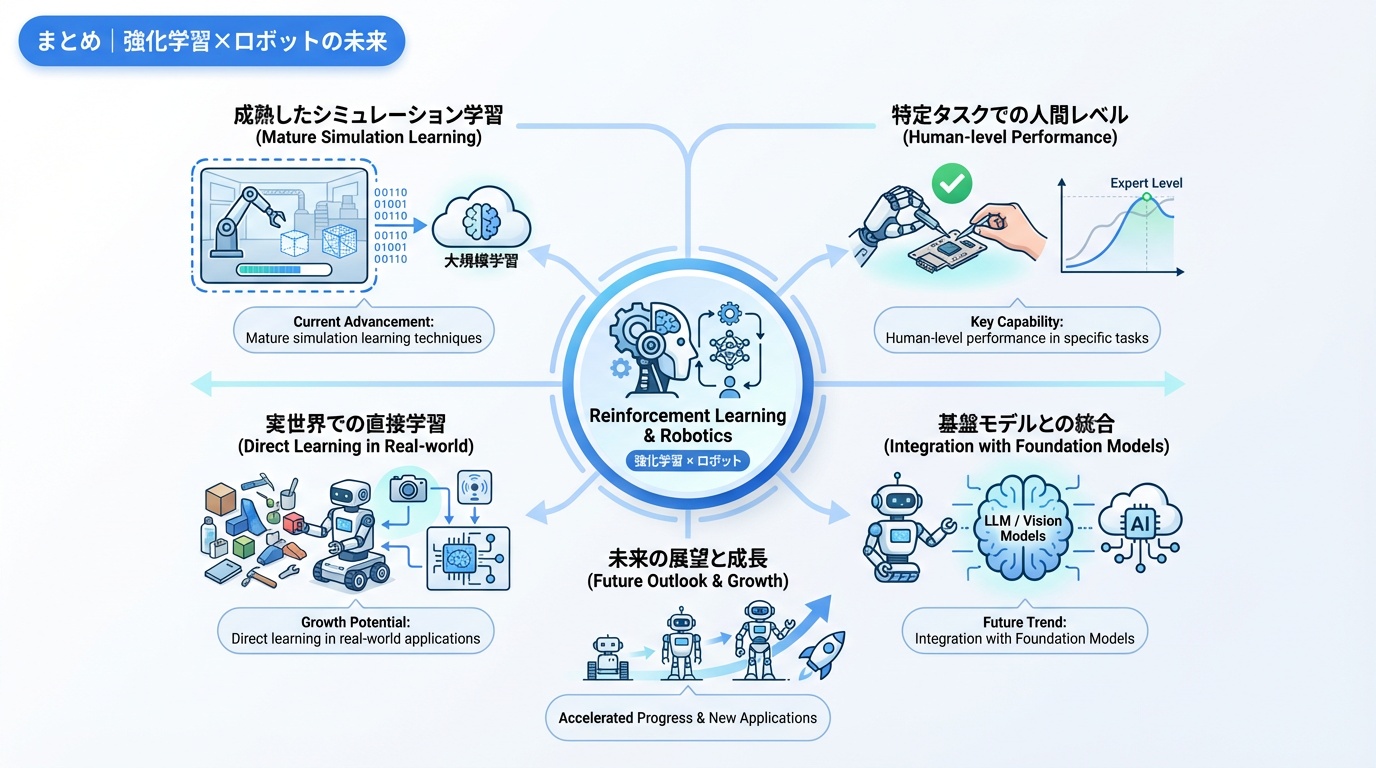
強化学習は、ロボットに人間を超える能力を与える可能性を持つ技術です。
現在の到達点
- シミュレーションでの学習技術は成熟
- Sim-to-Real技術で実機応用が現実的に
- 特定タスクでは人間を超える性能を達成
今後の展望
- Foundation Modelsとの融合による汎用化
- 実世界での直接学習技術の発展
- 家庭用ロボットへの応用拡大
- 人間とロボットの協調学習
関連記事としてフィジカルAIの動向もご覧ください。
https://ainow.jp/nvidia-groot-guide/


https://ainow.jp/robot-simulation-guide/

