

AINOW(エーアイナウ)編集部です。産業用ロボットや自律移動ロボットの普及が加速する中、ロボット制御の基礎知識はエンジニアにとって必須のスキルとなっています。本記事では、PID制御から最新のAI制御技術まで、ロボット制御の全体像を体系的に解説します。これからロボット開発を始める方も、制御理論を復習したい方もぜひ参考にしてください。
この記事のサマリー
- ロボット制御の基本概念からPID制御、運動学、モーションプランニングまで網羅的に解説
- 2026年最新の強化学習やMPC(モデル予測制御)など先進的な制御技術を紹介
- ROS2 Control、MoveIt2などの実践的な開発環境と学習ロードマップを提示
ロボット制御とは?
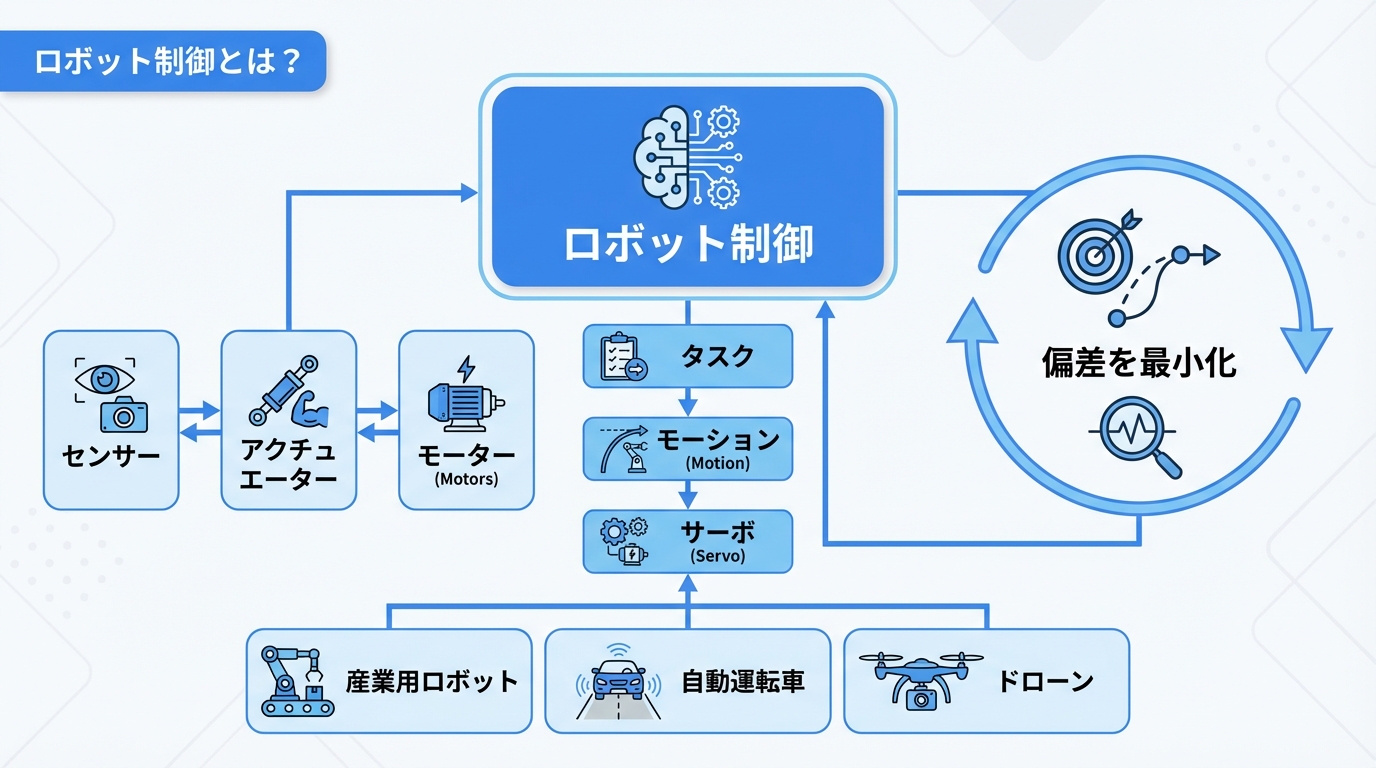
ロボット制御とは、ロボットを目的通りに動作させるための技術体系です。センサーからの情報を基に、モーターやアクチュエータに適切な指令を送り、所望の動作を実現します。製造業の産業用ロボットから、自動運転車、ドローン、サービスロボットまで、あらゆるロボットシステムの根幹を成す技術です。
ロボット制御の基本概念
ロボット制御の基本は、目標状態と現在状態の差を最小化することです。この差を「偏差」と呼び、偏差をゼロに近づけるためにアクチュエータを駆動します。制御システムは以下の要素で構成されます。
| 要素 | 役割 | 例 |
|---|---|---|
| センサー | 現在状態の計測 | エンコーダ、IMU、力センサー |
| コントローラー | 制御演算 | PID制御器、MPC |
| アクチュエータ | 物理的動作の実行 | サーボモーター、油圧シリンダ |
| プラント | 制御対象のシステム | ロボットアーム、移動ロボット |
制御の階層構造(タスク・動作・サーボ)
ロボット制御は一般的に3つの階層で構成されます。上位層ほど抽象度が高く、下位層ほどリアルタイム性が求められます。
|
この階層構造により、複雑なタスクを管理可能な単位に分割し、各層で最適化を行うことができます。詳しいロボットシステムの構成についてはROSの基礎ガイドも参照してください。
古典制御理論
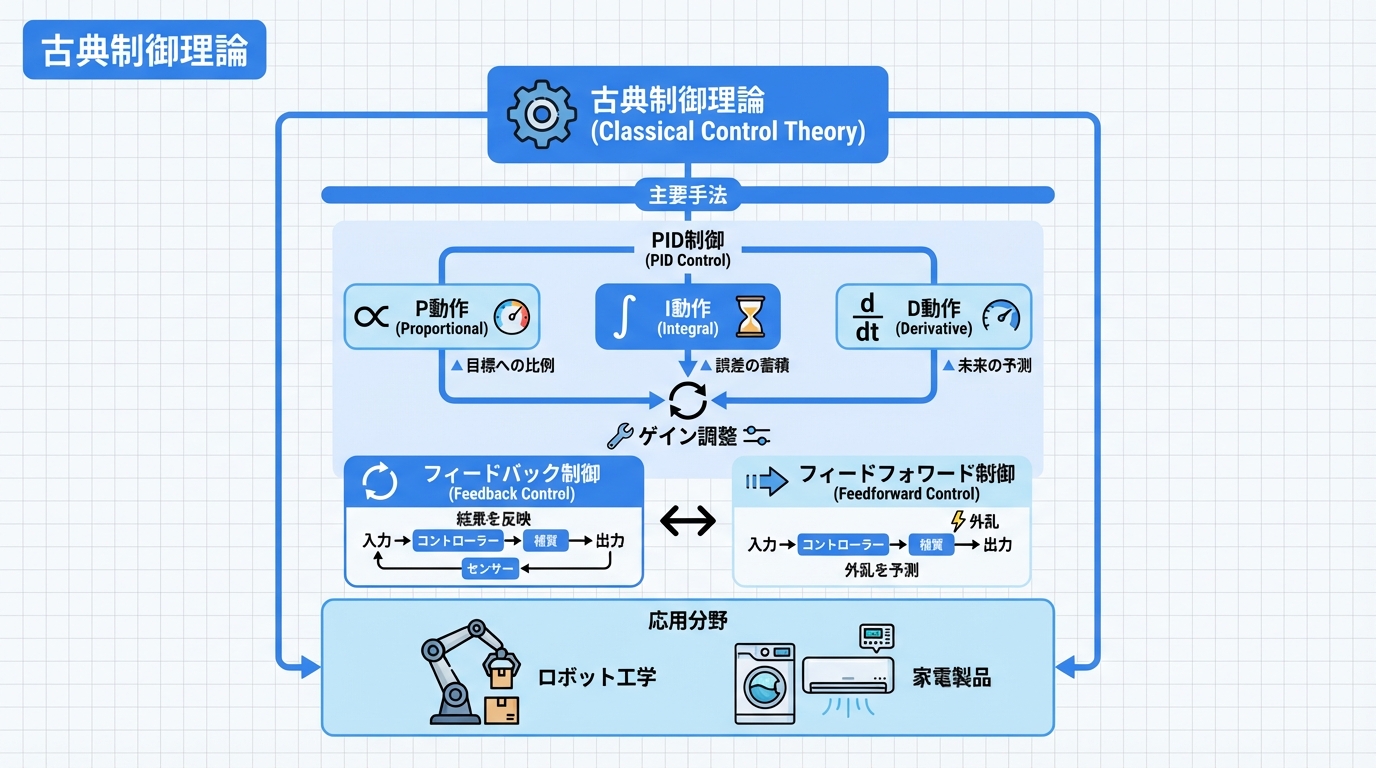
古典制御理論は、ロボット制御の基盤となる理論体系です。特にPID制御は、産業用ロボットから家電製品まで、最も広く使われている制御手法です。
PID制御の基礎
PID制御は、比例(P: Proportional)、積分(I: Integral)、微分(D: Derivative)の3つの要素を組み合わせた制御手法です。
| 要素 | 機能 | 効果 | 課題 |
|---|---|---|---|
| P(比例) | 偏差に比例した出力 | 応答速度向上 | 定常偏差が残る |
| I(積分) | 偏差の累積に比例した出力 | 定常偏差の除去 | オーバーシュート増加 |
| D(微分) | 偏差変化率に比例した出力 | 振動抑制 | ノイズに敏感 |
制御出力u(t)は以下の式で表されます:
u(t) = Kp*e(t) + Ki*∫e(t)dt + Kd*de(t)/dt
ゲイン調整(チューニング)
PID制御の性能は、各ゲイン(Kp, Ki, Kd)の値に大きく依存します。適切なチューニングには以下の手法があります。
|

AINOW編集部
|
実務では、まずPゲインのみで動作確認し、徐々にI、Dを追加する手順が効果的です。 |
フィードバック制御とフィードフォワード制御
フィードバック制御は、出力を測定して入力にフィードバックする閉ループ制御です。外乱に強い反面、応答に遅れが生じます。一方、フィードフォワード制御は、目標値から直接入力を計算する開ループ制御で、既知の外乱を事前に補償できます。
実際のロボット制御では、両者を組み合わせた2自由度制御がよく用いられます。
運動学と逆運動学
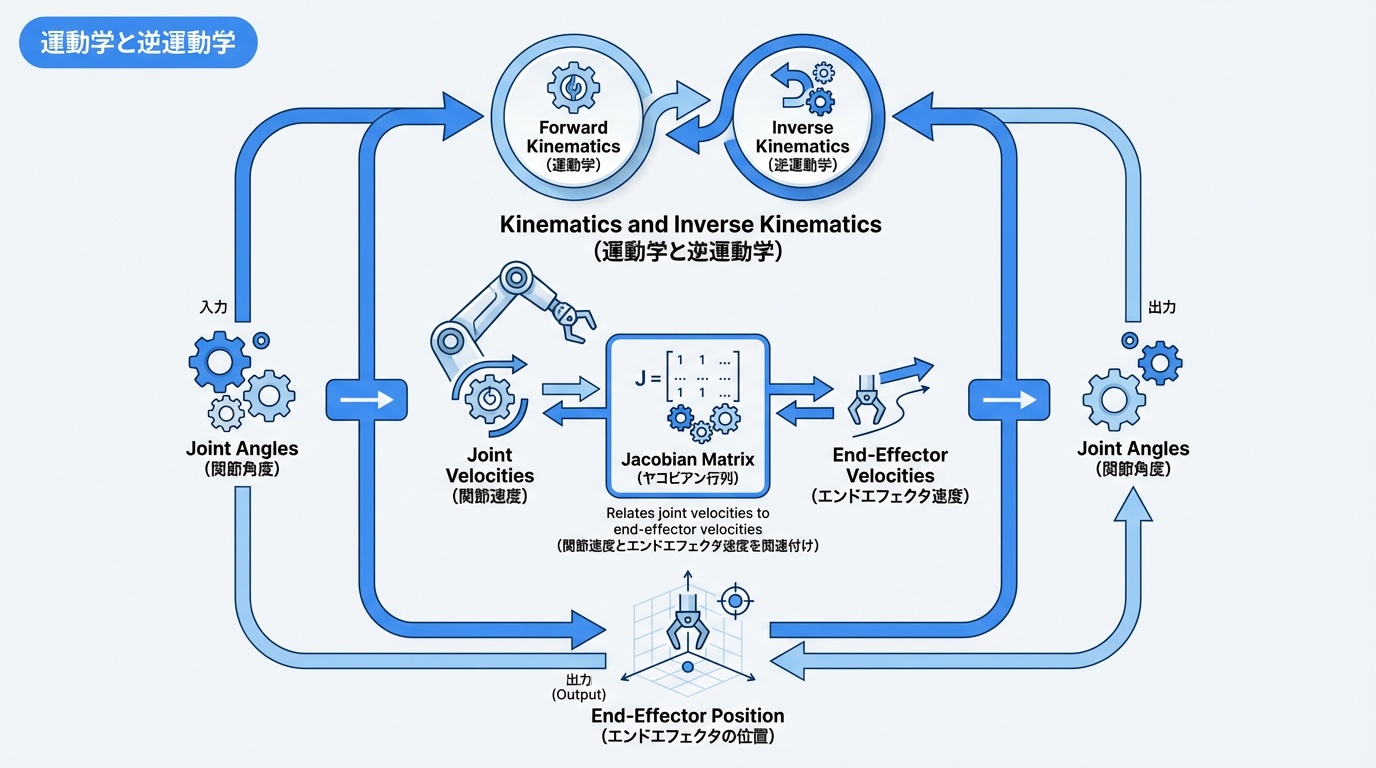
ロボットの運動を数学的に記述するのが運動学(キネマティクス)です。特にロボットアームの制御において、運動学の理解は不可欠です。詳しくはロボットアーム入門ガイドも参照してください。
順運動学(Forward Kinematics)
順運動学は、関節角度からエンドエフェクタの位置・姿勢を求める計算です。各リンクの変換行列を連鎖的に掛け合わせることで算出します。
6自由度ロボットアームの場合、ベースからエンドエフェクタまでの同次変換行列は以下のように表されます:
T = T1 * T2 * T3 * T4 * T5 * T6
各変換行列Tiは、DH(Denavit-Hartenberg)パラメータを用いて記述されることが一般的です。
逆運動学(Inverse Kinematics)
逆運動学は、目標位置・姿勢から必要な関節角度を求める計算です。順運動学の逆問題であり、一般に解が複数存在するか、解が存在しない場合があります。
| 解法 | 特徴 | 適用場面 |
|---|---|---|
| 解析解 | 高速、正確 | 特定の構造(6軸垂直多関節等) |
| 数値解 | 汎用性が高い | 一般的なロボット構造 |
| 機械学習 | 複雑な制約に対応 | 冗長自由度、障害物回避 |
ヤコビアン行列
ヤコビアン行列は、関節速度とエンドエフェクタ速度の関係を記述する行列です。
v = J(q) * q̇
ここでvはエンドエフェクタの速度、q̇は関節角速度、Jがヤコビアン行列です。ヤコビアンは以下の用途で重要です:
|
モーションプランニング
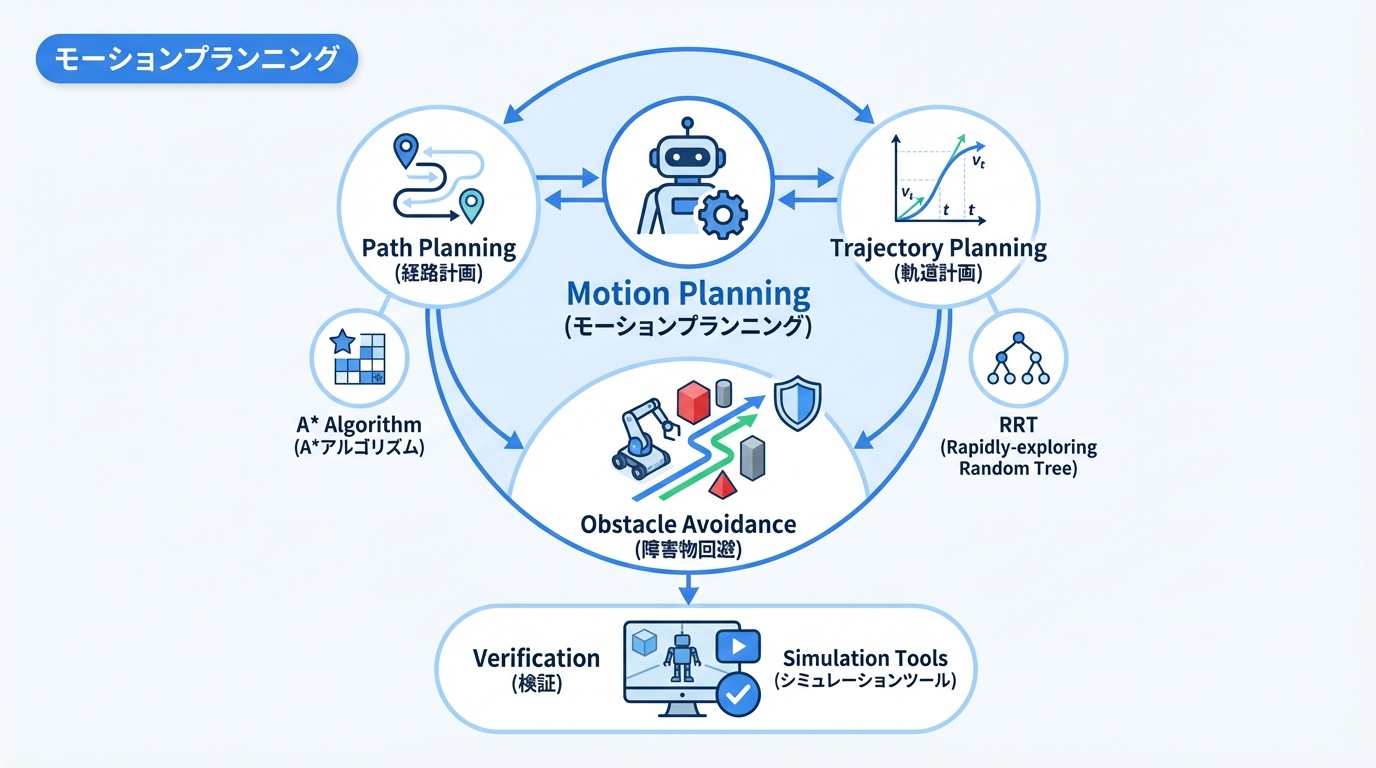
モーションプランニングは、ロボットが障害物を避けながら目標位置まで移動する経路を生成する技術です。ロボットシミュレーション入門で紹介しているシミュレータを使って検証できます。
経路計画(Path Planning)
経路計画は、時間を考慮せず、開始点から目標点までの衝突のない経路を見つける問題です。主なアプローチには以下があります:
| 手法 | 特徴 | 計算量 |
|---|---|---|
| グラフベース | 離散化した空間で探索 | O(V log V + E) |
| サンプリングベース | ランダムサンプリングで構成空間を探索 | 確率的完全性 |
| ポテンシャル場 | 仮想的な力場を利用 | O(n) |
軌道計画(Trajectory Planning)
軌道計画は、経路に時間情報を付加し、速度・加速度プロファイルを生成します。以下の制約を満たす必要があります:
|
代表的な軌道生成手法として、台形速度プロファイル、S字カーブ、多項式補間、スプライン補間があります。
RRT、A*アルゴリズム
A*アルゴリズムはグラフベースの最適経路探索アルゴリズムです。ヒューリスティック関数を用いて効率的に最短経路を見つけます。
RRT(Rapidly-exploring Random Tree)は、サンプリングベースの経路計画アルゴリズムです。高次元の構成空間でも効率的に動作し、以下の派生手法があります:
| アルゴリズム | 特徴 | 最適性 |
|---|---|---|
| RRT | 基本的なランダム探索 | なし |
| RRT* | 漸近的最適性を保証 | あり(漸近的) |
| RRT-Connect | 双方向探索で高速化 | なし |
| Informed RRT* | ヒューリスティックで収束改善 | あり(漸近的) |
|
AINOW編集部
|
2026年現在、MoveIt2ではBIT*やAIT*など最新のサンプリングベースプランナーも利用可能です。 |
力制御

力制御は、ロボットが環境と接触する際に必要な制御技術です。組立作業、研磨、人協働ロボットなど、力のやり取りが必要な場面で不可欠です。
インピーダンス制御
インピーダンス制御は、ロボットの動的特性(質量・ダンパ・バネ)を仮想的に設定し、外力に対する応答を制御します。位置指令型のロボットに適しています。
目標インピーダンスは以下の式で表されます:
F = M(ẍd - ẍ) + D(ẋd - ẋ) + K(xd - x)
M、D、Kはそれぞれ仮想質量、仮想ダンパ、仮想バネ係数です。
アドミタンス制御
アドミタンス制御は、力入力から位置出力を生成する制御です。力センサーで計測した外力に基づき、ロボットの動きを決定します。力指令型のロボットに適しています。
| 制御方式 | 入力 | 出力 | 適用 |
|---|---|---|---|
| インピーダンス | 位置偏差 | 力 | 位置制御型ロボット |
| アドミタンス | 力 | 位置指令 | 高剛性ロボット |
ハイブリッド位置/力制御
ハイブリッド制御は、タスク空間を位置制御方向と力制御方向に分割し、それぞれ独立に制御する手法です。例えば、研磨作業では表面に垂直な方向は力制御、表面に平行な方向は位置制御を行います。
|
ビジョンベース制御
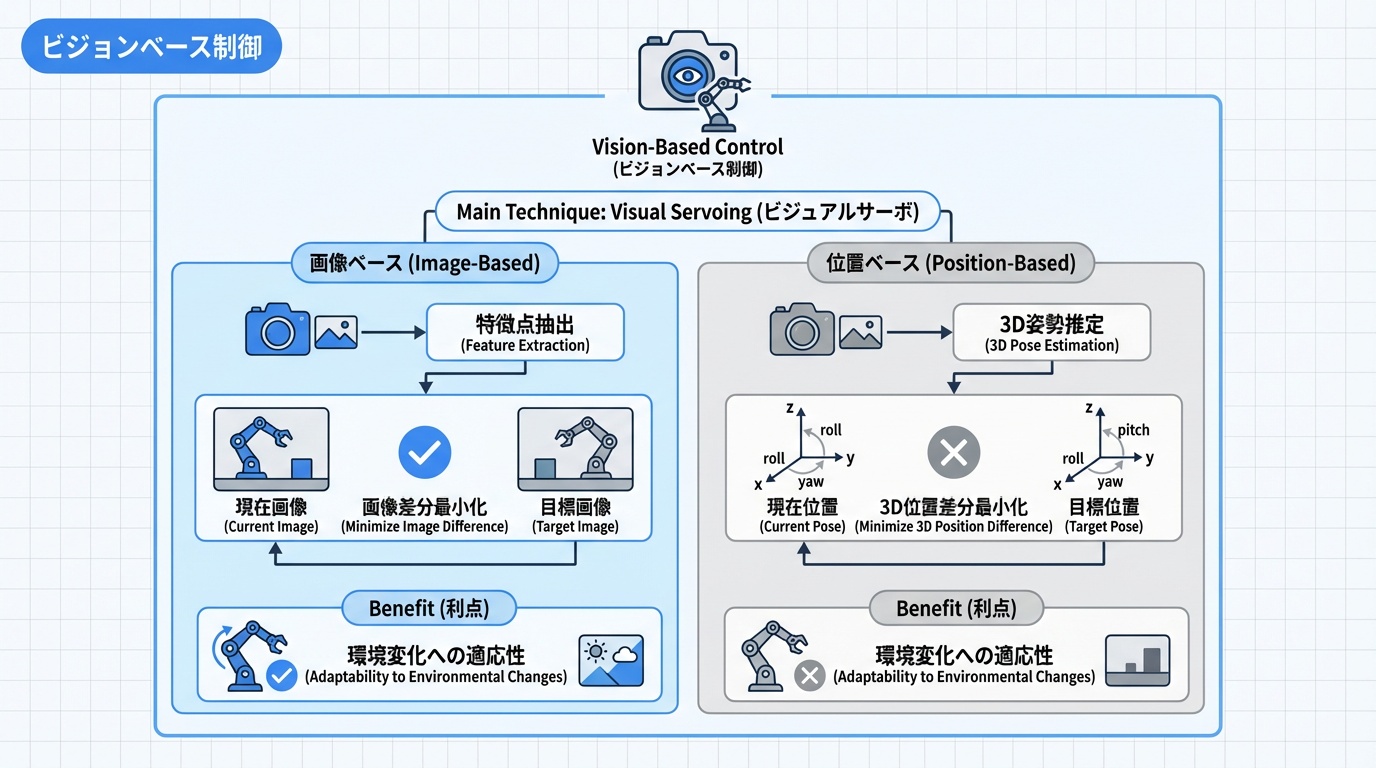
ビジョンベース制御は、カメラ画像を用いてロボットを制御する技術です。環境の変化に適応し、柔軟な作業が可能になります。
Visual Servoing
Visual Servoing(ビジュアルサーボ)は、画像特徴量をフィードバックしてロボットを制御する手法です。目標画像と現在画像の差を最小化するようにロボットを動かします。
|
画像ベース vs 位置ベース
Visual Servoingには主に2つのアプローチがあります:
| 方式 | 特徴量 | メリット | デメリット |
|---|---|---|---|
| IBVS(画像ベース) | 画像座標上の特徴点 | キャリブレーション誤差に強い | 経路予測が困難 |
| PBVS(位置ベース) | 3D位置・姿勢 | 経路が直線的 | キャリブレーション精度に依存 |
| ハイブリッド | 両方の組み合わせ | 両者の利点を活用 | 設計が複雑 |
|
AINOW編集部
|
深層学習の発展により、End-to-End Visual Servoingが注目を集めています。 |
最新制御技術(2026年)
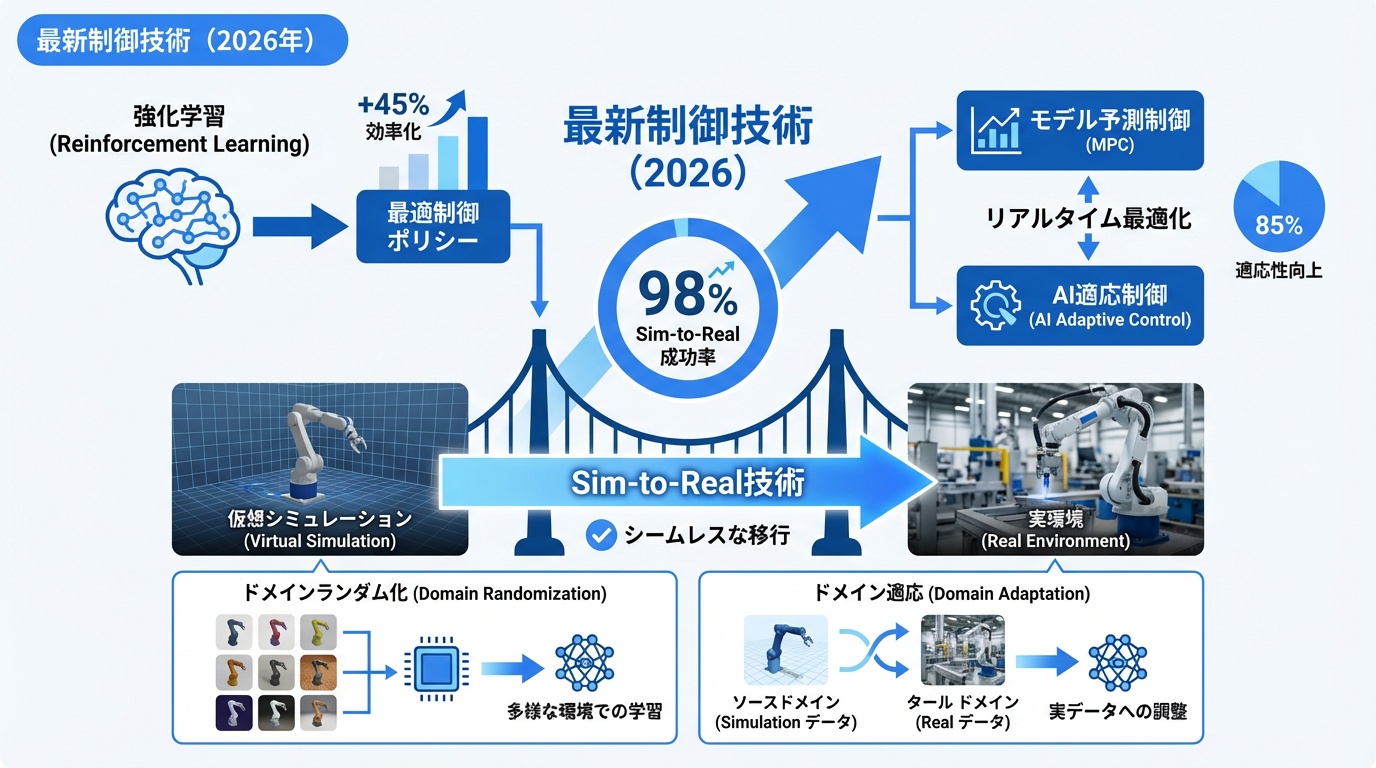
2026年現在、AI技術の進歩により、ロボット制御は大きな変革期を迎えています。従来の制御理論とAIを融合した新しいアプローチが実用化されつつあります。
強化学習による制御
強化学習(Reinforcement Learning)は、試行錯誤を通じて最適な制御方策を学習する手法です。複雑な動作の獲得や、モデル化困難な系の制御に有効です。
| アルゴリズム | 特徴 | 応用例 |
|---|---|---|
| SAC(Soft Actor-Critic) | サンプル効率が高い | マニピュレーション |
| PPO(Proximal Policy Optimization) | 安定した学習 | 歩行ロボット |
| TD3(Twin Delayed DDPG) | 連続行動空間に適している | 産業用ロボット |
シミュレータで学習したポリシーを実機に転移するSim-to-Real技術も進歩しており、ドメインランダマイゼーションやドメイン適応が活用されています。
モデル予測制御(MPC)
MPC(Model Predictive Control)は、システムモデルを用いて未来の状態を予測し、最適な制御入力を計算する手法です。
|
2026年現在、Neural MPCやlearned dynamicsモデルを用いたMPCが研究されており、モデル化困難な系への適用が進んでいます。
AIによる適応制御
AIを活用した適応制御は、環境変化やシステム変動に自動で適応する制御系を実現します:
| 技術 | 機能 | 利点 |
|---|---|---|
| オンライン学習 | 実行中にモデルを更新 | 環境変化への追従 |
| メタ学習 | 少数サンプルで新タスクに適応 | 汎化能力の向上 |
| Foundation Models | 大規模事前学習モデルの活用 | ゼロショット/フューショット適応 |
制御開発環境
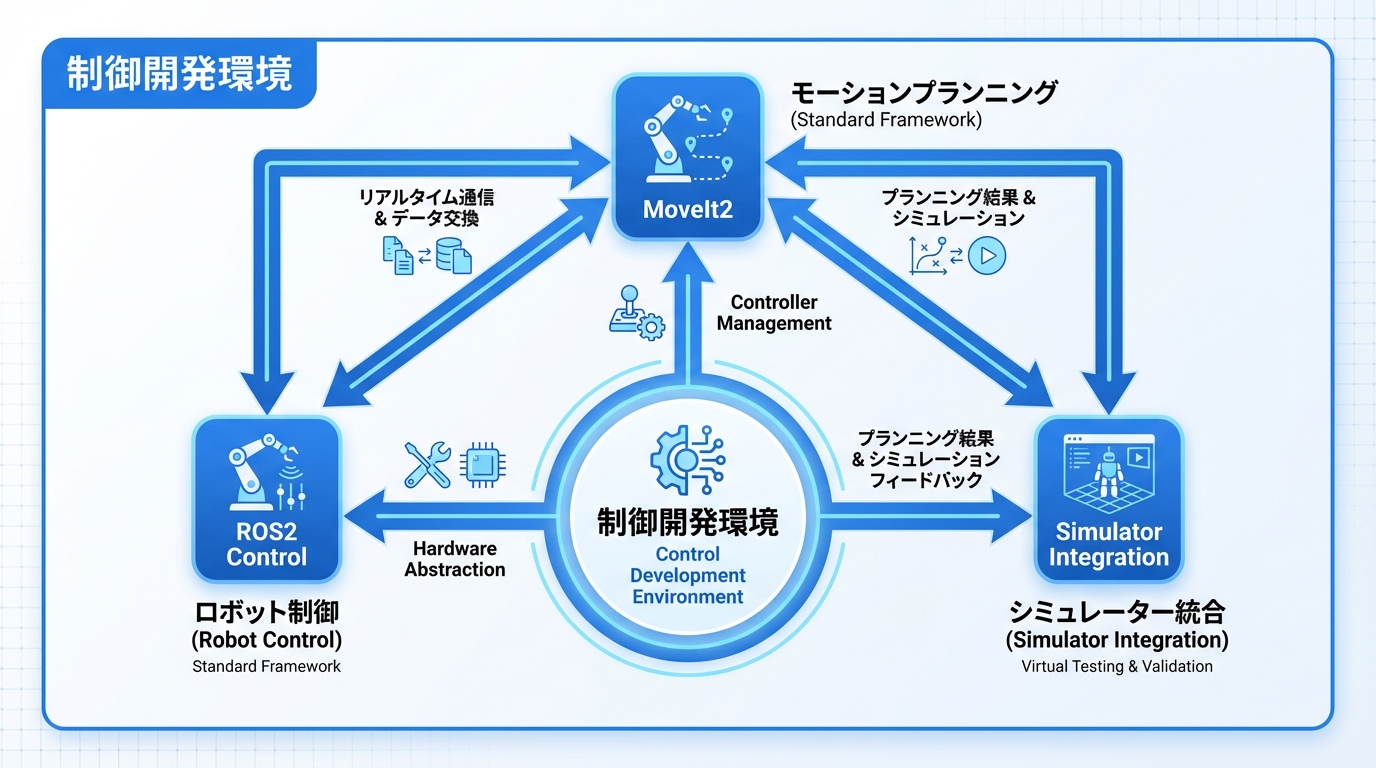
実際のロボット制御開発には、適切なソフトウェアフレームワークの選択が重要です。ROSの基礎ガイドでは、より詳しい解説を行っています。
ROS2 Control
ros2_controlは、ROS2におけるロボット制御の標準フレームワークです。ハードウェア抽象化とコントローラー管理を提供します。
|
MoveIt2
MoveIt2は、ROS2におけるモーションプランニングの標準フレームワークです。ロボットアーム入門で紹介しているようなマニピュレータの制御に広く使われています。
| 機能 | 説明 |
|---|---|
| Motion Planning | OMPL統合による多様なプランニングアルゴリズム |
| Kinematics | 順/逆運動学ソルバー(KDL、IKFast、TRAC-IK等) |
| Collision Detection | FCL/Bulletによる高速衝突検出 |
| Trajectory Execution | ros2_controlとの連携 |
シミュレータ連携
ロボット制御の開発・検証には、シミュレータが不可欠です。ロボットシミュレーション入門で各シミュレータの特徴を解説しています。
| シミュレータ | 特徴 | 主な用途 |
|---|---|---|
| Gazebo | ROS標準、物理エンジン統合 | 一般的なロボット開発 |
| Isaac Sim | NVIDIA GPU活用、フォトリアル | 深層学習、Sim-to-Real |
| MuJoCo | 高速、接触計算に強い | 強化学習研究 |
| PyBullet | Pythonネイティブ、軽量 | プロトタイピング |
|
AINOW編集部
|
2026年現在、Isaac SimはROS2との連携が強化され、産業界での採用が増加しています。 |
まとめ|ロボット制御の学習ロードマップ
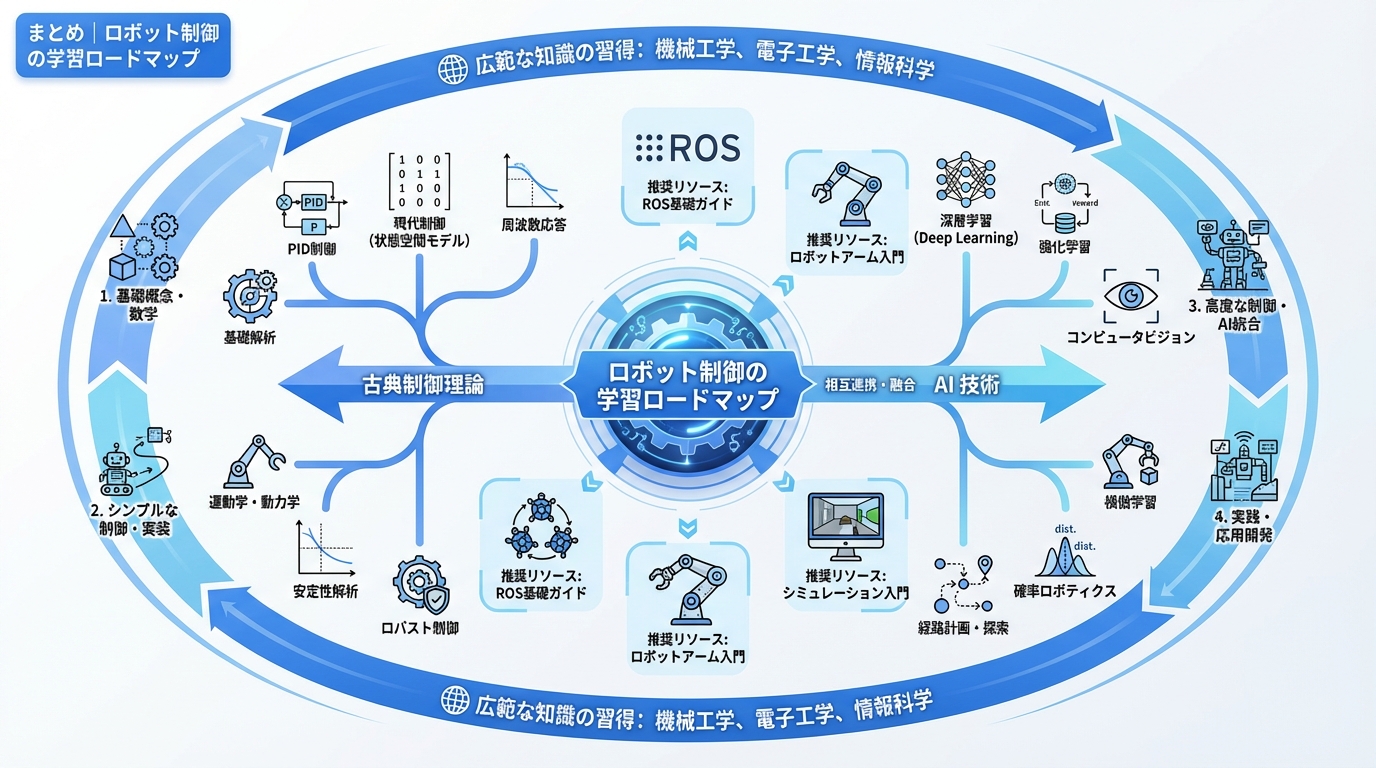
ロボット制御は、古典制御理論から最新のAI技術まで幅広い知識が求められる分野です。以下の学習ロードマップを参考に、段階的にスキルを習得することを推奨します。
| 段階 | 学習内容 | 目安期間 |
|---|---|---|
| 基礎 | PID制御、古典制御理論 | 1-2ヶ月 |
| 運動学 | 順/逆運動学、ヤコビアン | 1-2ヶ月 |
| プランニング | 経路計画、軌道計画 | 1-2ヶ月 |
| 実装 | ROS2 Control、MoveIt2 | 2-3ヶ月 |
| 応用 | 力制御、ビジョン制御 | 2-3ヶ月 |
| 先端 | 強化学習、MPC、AIベース制御 | 3ヶ月以上 |
|
ロボット制御の学習を進める際は、ROSの基礎ガイド、ロボットアーム入門、シミュレーション入門もあわせてご覧ください。
よくある質問
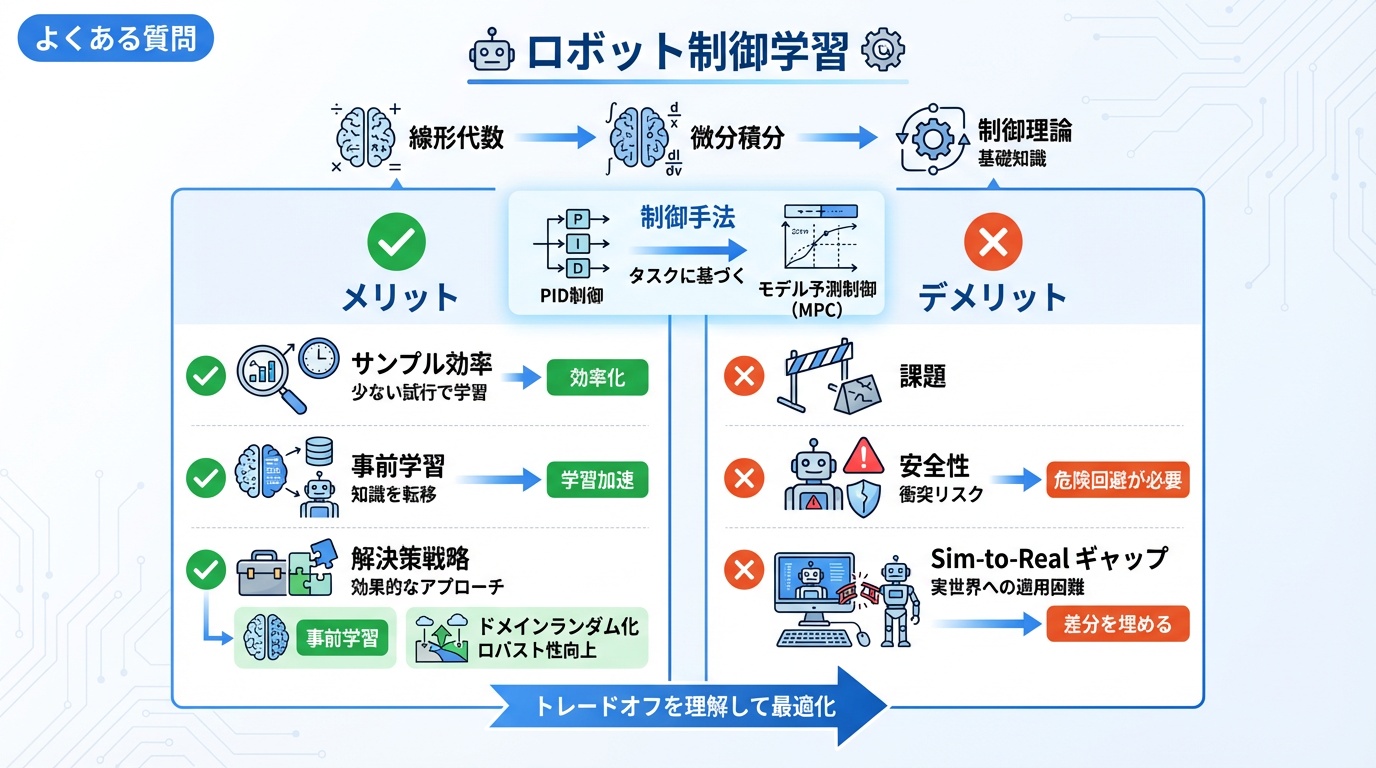
Q. ロボット制御を学ぶのに必要な数学の知識は?
A. 線形代数(行列演算、固有値)、微分積分、古典制御理論(ラプラス変換、伝達関数)が基礎として必要です。より高度な制御には最適化理論や確率論の知識も役立ちます。
Q. PID制御とMPCはどちらを使うべきですか?
A. シンプルな制御タスクにはPID、制約を考慮した最適化が必要な場合はMPCが適しています。計算リソースと要求性能のバランスで選択してください。
Q. 強化学習をロボット制御に使う際の課題は?
A. サンプル効率の低さ、安全性の確保、Sim-to-Realギャップが主な課題です。シミュレータでの事前学習とドメインランダマイゼーションで軽減できます。
Q. ROS2 Controlを使うメリットは?
A. ハードウェア抽象化により、異なるロボットに同じコントローラを適用できます。また、豊富な標準コントローラとMoveIt2との連携が利点です。
Q. 力制御を実装するには何が必要ですか?
A. 力/トルクセンサー、リアルタイム制御可能なハードウェア、適切な制御周期(1kHz程度)が必要です。ros2_controlのforce_controllersパッケージが参考になります。



 GitHub Copilot
GitHub Copilot Replit Agent
Replit Agent Cline
Cline Dify
Dify Jinbaflow
Jinbaflow
