

AINOW(エーアイナウ)編集部です。マルチモーダルAIの進化が止まりません。テキスト、画像、音声、動画を統合的に処理するAI技術は、今や多くのビジネスシーンでの活用が期待されています。特に2026年には、OpenAIのChatGPTをはじめとする主要なAIモデルがこの分野での機能を大幅に強化しました。この記事を読むことで、最新のマルチモーダルAI技術についての理解を深め、用途に応じた最適なモデルの選び方を知ることができます。
マルチモーダルAIとは

マルチモーダルAIとは、テキスト、画像、音声、動画など複数の情報形式を統合的に処理できるAI技術です。従来のLLMがテキストのみを扱っていたのに対し、マルチモーダルAIは「見る」「聞く」「読む」を統合的に処理します。
ChatGPT・OpenAIについてより詳しく知りたい方は、ChatGPT完全ガイドをご覧ください。
マルチモーダルの定義
「モダリティ」とは情報の形式を指し、以下のような種類があります。
- テキスト:文章、コード、構造化データ
- 画像:写真、図表、スクリーンショット、手書き文字
- 音声:音声入力、音楽、環境音
- 動画:映像コンテンツ、画面録画
マルチモーダルAIはこれらを単独で処理するだけでなく、複数のモダリティを組み合わせた理解が可能です。例えば「この画像について質問に答える」「動画の内容を要約する」といったタスクを実行できます。
なぜマルチモーダルが重要か
人間の認知は本来マルチモーダルです。私たちは文字を読みながら図を見て、音声を聞きながら映像を観ます。AIがこの能力を獲得することで、より自然で実用的なインタラクションが可能になります。
主要モデルのマルチモーダル機能比較
2026年現在、マルチモーダル機能を備えた主要LLMとして、OpenAIのGPT-4o、GoogleのGemini 2.5 Pro、AnthropicのClaude 4があります。それぞれの特徴と強みを比較します。
GPT-4o(OpenAI)
GPT-4oは「omni(全方向)」を意味し、テキスト・画像・音声を単一のAPIで統合的に処理できます。2024年5月にリリースされ、リアルタイム音声対話と画像理解を同時に実現しました。2026年1月には、Cerebrasとの提携により、750MWの高速AIコンピュートを追加し、リアルタイムAI処理の速度をさらに向上させました。
- 画像入力:写真、スクリーンショット、文書画像を理解
- 音声入出力:自然な音声対話、感情表現
- 処理速度:GPT-4 Turboより2倍高速
- API料金:GPT-4 Turboより50%安価
Gemini 2.5 Pro(Google DeepMind)
Gemini 2.5 Proは、Googleが開発したマルチモーダルネイティブのLLMです。設計段階からマルチモーダルを前提としており、画像・動画・音声の処理能力が特に優れています。
- 動画理解:長時間動画(最大3時間)の内容理解
- 100万トークン:業界最大のコンテキストウィンドウ
- Google連携:Search、YouTube、Mapsとの統合
- コード実行:実行環境での動的処理
Claude 4(Anthropic)
Claude 4は画像理解に対応していますが、画像・動画の生成機能は持ちません。テキスト処理と安全性を重視した設計で、ドキュメント分析や長文処理に強みを持ちます。2026年3月には、メモリ機能が無料プランでも利用可能になり、他のチャットボットからの乗り換えが容易になっています(参考:The Verge)。
- 画像分析:図表、グラフ、文書の詳細な理解
- 長文処理:20万トークンのコンテキスト
- 安全性:Constitutional AIによる安全設計
- コーディング:複雑なコード生成・レビュー
|
画像理解能力の詳細比較
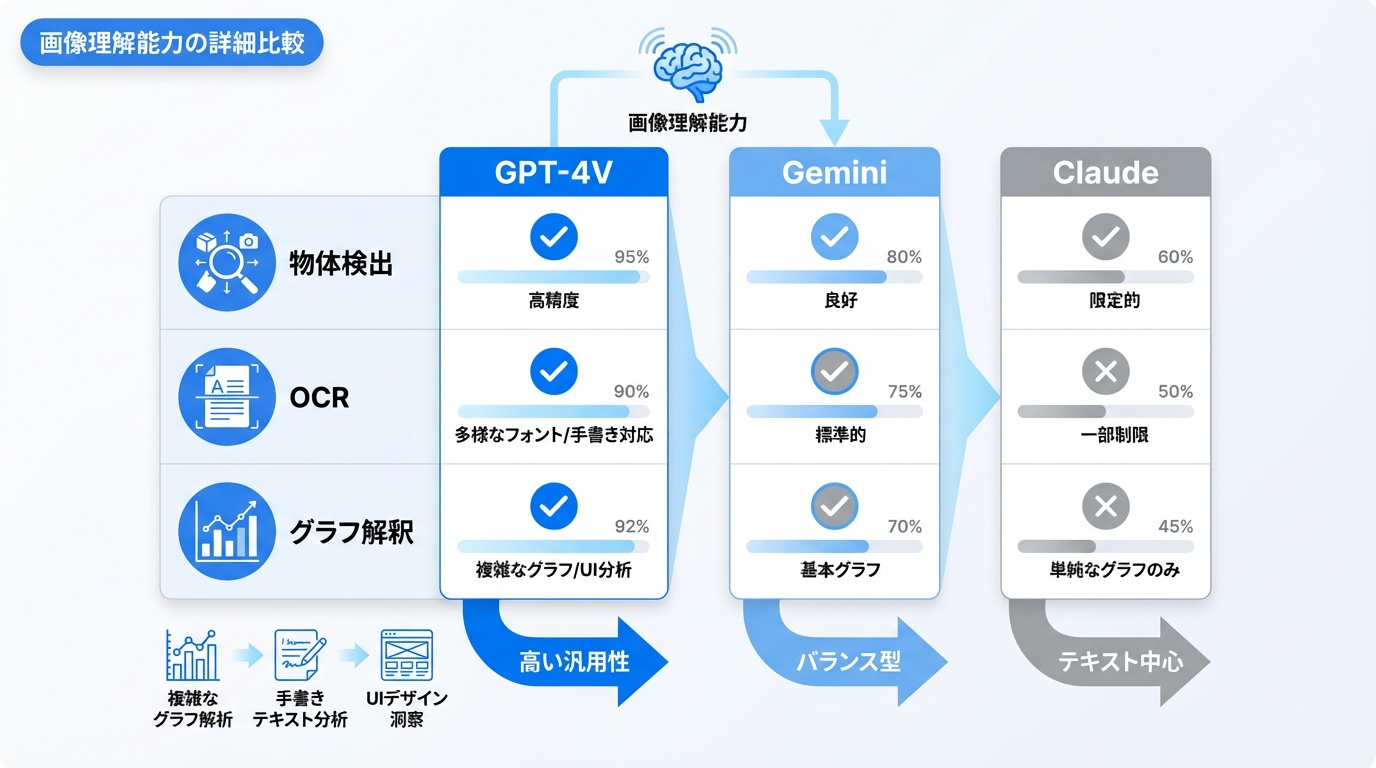
マルチモーダルAIの中核機能である画像理解について、各モデルの能力を詳しく比較します。
GPT-4Vの画像理解
GPT-4V(Vision)は、画像からの情報抽出において高い汎用性を持ちます。写真の説明、OCR(文字認識)、図表の解釈、画像内の物体検出など幅広いタスクに対応します。
得意なタスク:
- 複雑な図表やグラフの解釈
- 手書き文字のOCR
- 画像内のテキスト翻訳
- UIデザインの分析・改善提案
Geminiの画像処理
Geminiは画像理解においてベンチマーク最高水準を記録しています。特にMMMU(Massive Multi-discipline Multimodal Understanding)テストで優れた成績を収めており、学術的・専門的な画像解析に強みを持ちます。
得意なタスク:
- 学術論文の図表解析
- 医療画像の説明
- 建築図面の理解
- 複数画像の横断比較
Claudeの画像分析
Claudeは画像生成機能を持たない代わりに、画像の詳細な分析と説明に特化しています。ビジネス文書やプレゼンテーションの解析において、文脈を踏まえた深い洞察を提供します。
得意なタスク:
- ビジネス文書の詳細分析
- データ可視化の解釈
- 技術文書の図解理解
- 長文レポートとの統合分析
| 💡 ワンポイント マルチモーダルAIの選定は、用途に応じて最適なモデルを選ぶことが重要です。特に画像理解を重視するなら、専門的な解析能力を持つモデルを選びましょう。 |
動画・音声への対応状況
マルチモーダルAIの進化において、動画と音声の処理能力は重要な差別化要因となっています。
動画理解の比較
| モデル | 動画入力 | 最大長 | リアルタイム処理 |
|---|---|---|---|
| GPT-4o | △(静止画抽出) | 制限あり | 音声のみ |
| Gemini 2.5 Pro | ◎ | 3時間 | ○ |
| Claude 4 | × | 非対応 | × |
Gemini 2.5 Proが動画処理において圧倒的な優位性を持っています。YouTubeとの統合により、動画の内容要約、特定シーンの検索、文字起こしなどを高精度で実行できます。
音声処理の比較
| モデル | 音声入力 | 音声出力 | リアルタイム対話 |
|---|---|---|---|
| GPT-4o | ◎ | ◎ | ◎ |
| Gemini 2.5 Pro | ○ | ○ | ○ |
| Claude 4 | × | × | × |
音声対話においてはGPT-4oが最も優れており、自然な抑揚や感情を伴った音声出力が可能です。Geminiも音声対応していますが、GPT-4oほどの自然さには達していません。
実践的な使い分けガイド
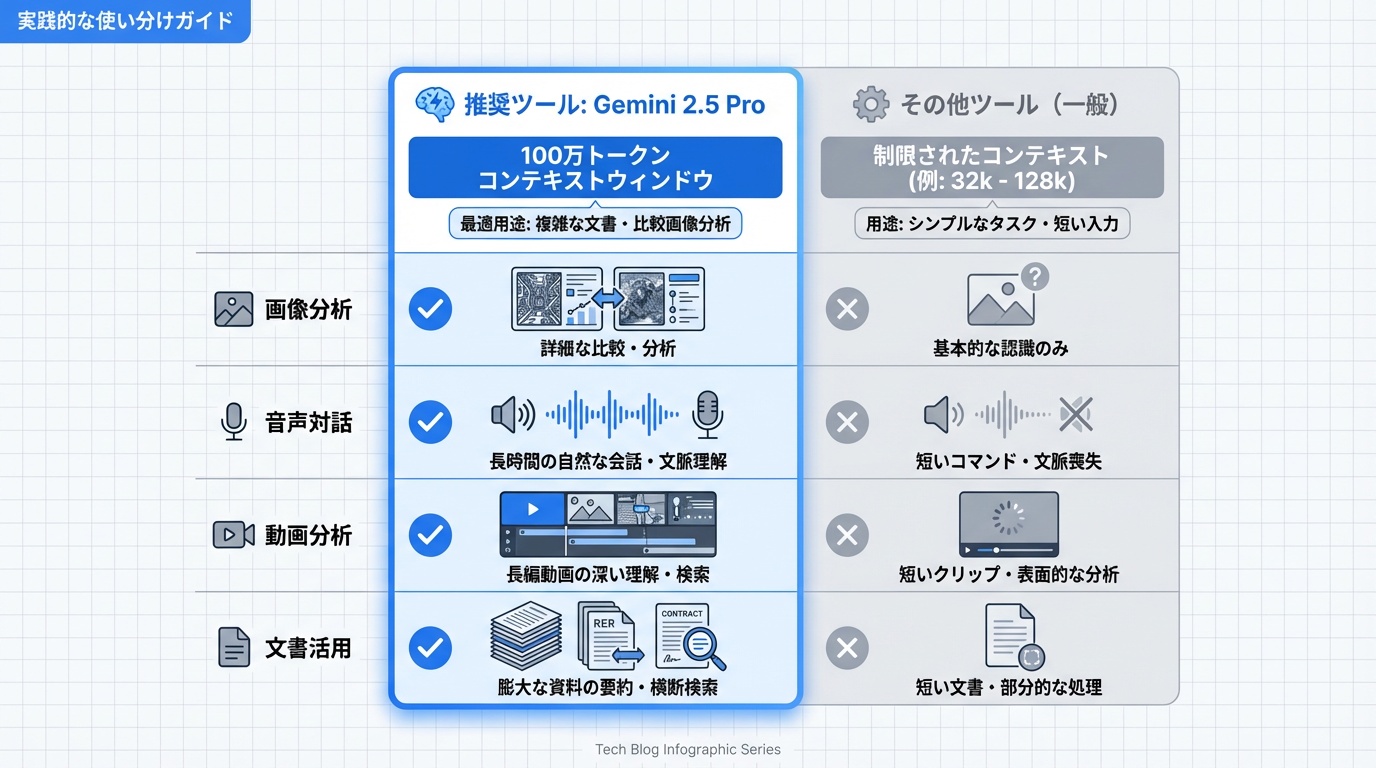
用途に応じた最適なマルチモーダルAIの選び方を解説します。
画像分析メインの場合
推奨:Gemini 2.5 Pro
学術論文、技術文書、複雑な図表の解析にはGeminiが最適です。特に複数の画像を横断的に比較分析するタスクでは、100万トークンのコンテキストウィンドウが威力を発揮します。
音声対話メインの場合
推奨:GPT-4o
カスタマーサポート、音声アシスタント、リアルタイム通訳などの用途にはGPT-4oが最適です。感情を伴った自然な音声出力と低レイテンシーのリアルタイム処理が強みです。
動画コンテンツ分析の場合
推奨:Gemini 2.5 Pro
YouTube動画の要約、講義動画からのメモ作成、映像コンテンツの検索にはGeminiが圧倒的に有利です。最大3時間の動画を一度に処理できる能力は他のモデルにはありません。
文書中心のビジネス利用
推奨:Claude 4
長文レポートの分析、契約書のレビュー、技術文書の作成など、テキスト処理が中心の業務にはClaudeが適しています。画像を含む文書の分析も可能で、安全性を重視した設計が企業利用に適しています。
|
APIと料金比較

マルチモーダル機能のAPI利用における料金体系を比較します。
料金比較表(2026年1月時点)
| モデル | 入力(1M tokens) | 出力(1M tokens) | 画像処理 |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | トークン換算 |
| Gemini 2.5 Pro | $1.25 | $5.00 | トークン換算 |
| Claude 4 Opus | $15.00 | $75.00 | トークン換算 |
| Claude 4 Sonnet | $3.00 | $15.00 | トークン換算 |
コストパフォーマンスではGeminiが優位ですが、用途によってはGPT-4oやClaudeの方が適している場合もあります。💡 ワンポイント 利用目的に応じて最適なプランを選びましょう。
ベンチマーク比較
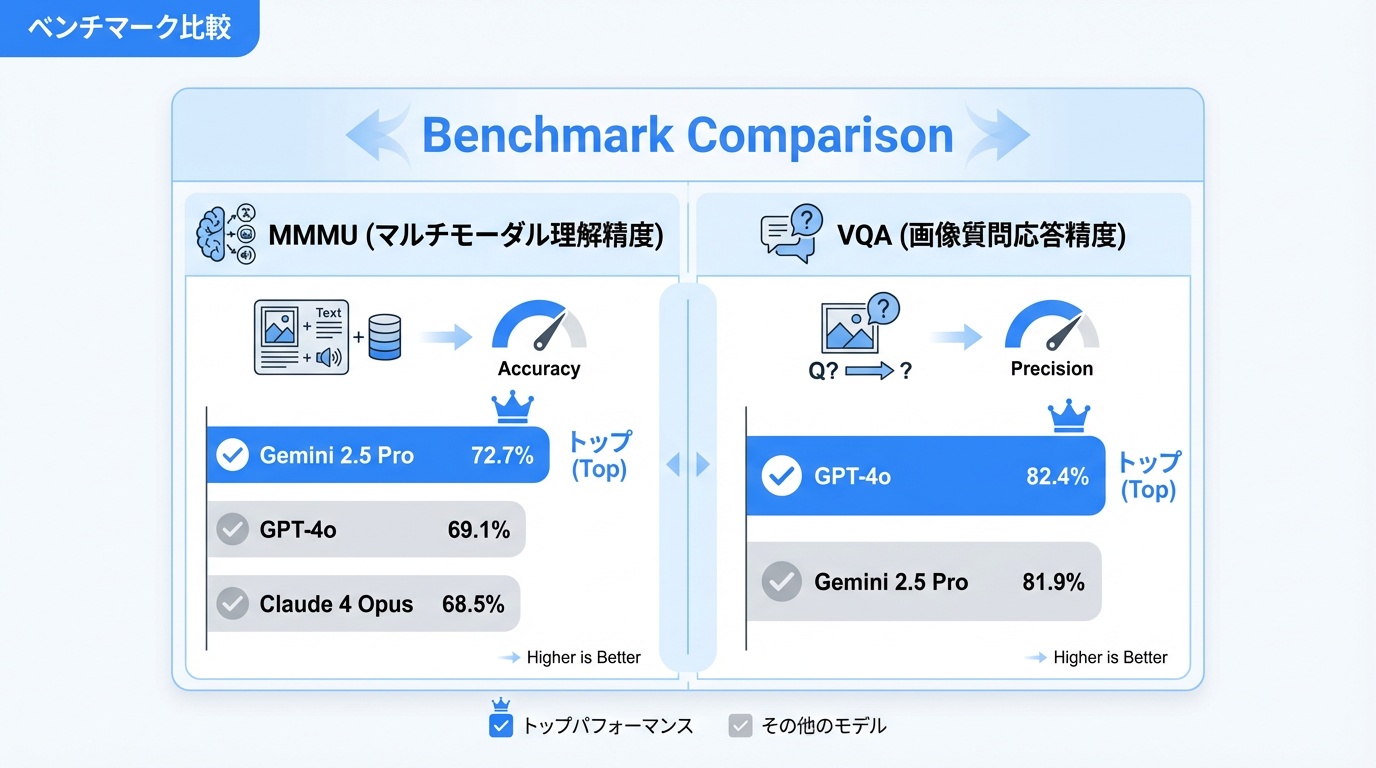
各モデルのマルチモーダル能力を客観的に評価するベンチマーク結果を紹介します。
MMMU(マルチモーダル理解)
MMMUは学術的なマルチモーダル理解を測定するベンチマークです。
- Gemini 2.5 Pro:72.7%(トップ)
- GPT-4o:69.1%
- Claude 4 Opus:68.5%
VQA(Visual Question Answering)
画像に関する質問応答の精度を測定します。
- GPT-4o:82.4%(トップ)
- Gemini 2.5 Pro:81.9%
- Claude 4 Opus:79.2%
今後の展望

マルチモーダルAIは急速に進化しており、2026年以降も大きな発展が予想されます。
短期的なトレンド(2026年)
- リアルタイム動画処理:ライブ映像のリアルタイム分析
- 3D理解:空間認識と3Dモデル生成
- 触覚情報:ロボティクスとの連携による触覚フィードバック
長期的な方向性
- 統合センシング:IoTデバイスからの多様なセンサーデータ統合
- 世界モデル:物理世界のシミュレーションと予測
- エンボディメント:ロボットとの統合によるPhysical AI
まとめ
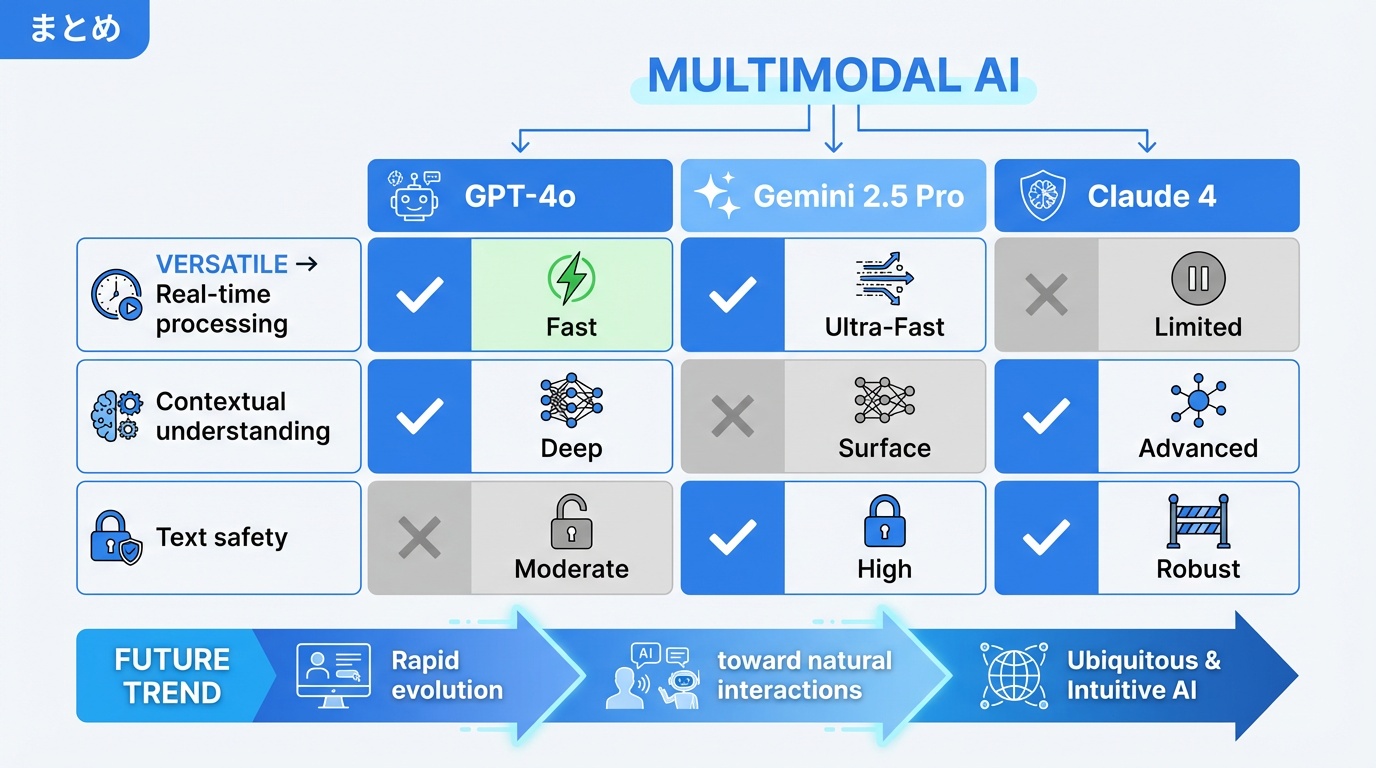
マルチモーダルAIは、テキスト・画像・音声・動画を統合的に処理できる次世代AI技術です。2026年現在、各モデルは以下のような特徴を持っています。
- GPT-4o:音声対話とリアルタイム処理に最適、汎用性が高い
- Gemini 2.5 Pro:動画理解と大容量コンテキストに最適、Google連携が強み
- Claude 4:テキスト処理と安全性に最適、ビジネス利用に適する
用途に応じて適切なモデルを選択することで、マルチモーダルAIの能力を最大限に活用できます。今後もこの分野は急速に進化し、より自然で強力なAIインタラクションが実現していくでしょう。
関連ニュースとして、Defense Secretary Pete HegsethがAnthropicをサプライチェーンリスクとして指定したことが報じられています。この動きは、AIモデルの安全性と信頼性に対する関心が高まっていることを示しています(参考:The Verge)。
https://ainow.jp/embodied-ai-guide/



https://ainow.jp/ai-coding-tools-comparison-2026/


よくある質問
Q. マルチモーダルAIとは何ですか?
A. マルチモーダルAIは、テキスト、画像、音声、動画など複数の情報形式を統合的に処理できるAI技術です。自然なインタラクションを実現するために開発されています。
Q. GPT-4oの特徴は何ですか?
A. GPT-4oはテキスト、画像、音声を統合的に処理できるモデルで、特に音声対話とリアルタイム処理に優れています。詳細はこちらをご覧ください。
Q. Gemini 2.5 Proは何が得意ですか?
A. Gemini 2.5 Proは長時間動画の理解や大容量コンテキスト処理に優れています。Googleサービスとの連携も強みです。
Q. Claude 4はどのような用途に向いていますか?
A. Claude 4はテキスト処理と安全性を重視した設計で、ビジネス文書の分析や契約書のレビューなどに向いています。
Q. マルチモーダルAIの料金はどうなっていますか?
A. モデルによって異なりますが、一般的にテキスト、画像、音声それぞれの処理に応じた料金が発生します。詳細は料金比較表をご参照ください。
Q. マルチモーダルAIの今後の展望は?
A. 今後はリアルタイム動画処理や3D理解、IoTデータの統合など、さらなる進化が期待されています。
Q. マルチモーダルAIはどのようなビジネスに役立ちますか?
A. マルチモーダルAIは、カスタマーサポート、マーケティング、データ分析、教育など、多岐にわたるビジネス分野で活用が見込まれています。
https://ainow.jp/chatgpt-api-guide

