

Embodied AI(身体性AI)は、物理的な身体を持ち、現実世界で行動できるAIを指します。2025年を境にロボティクス分野で急速に注目を集め、2026年は「Physical AI元年」とも呼ばれています。
本記事では、Embodied AIの基本概念から、主要な基盤モデル、市場動向、そして今後の展望まで、この革新的な技術領域を包括的に解説します。
Embodied AIとは
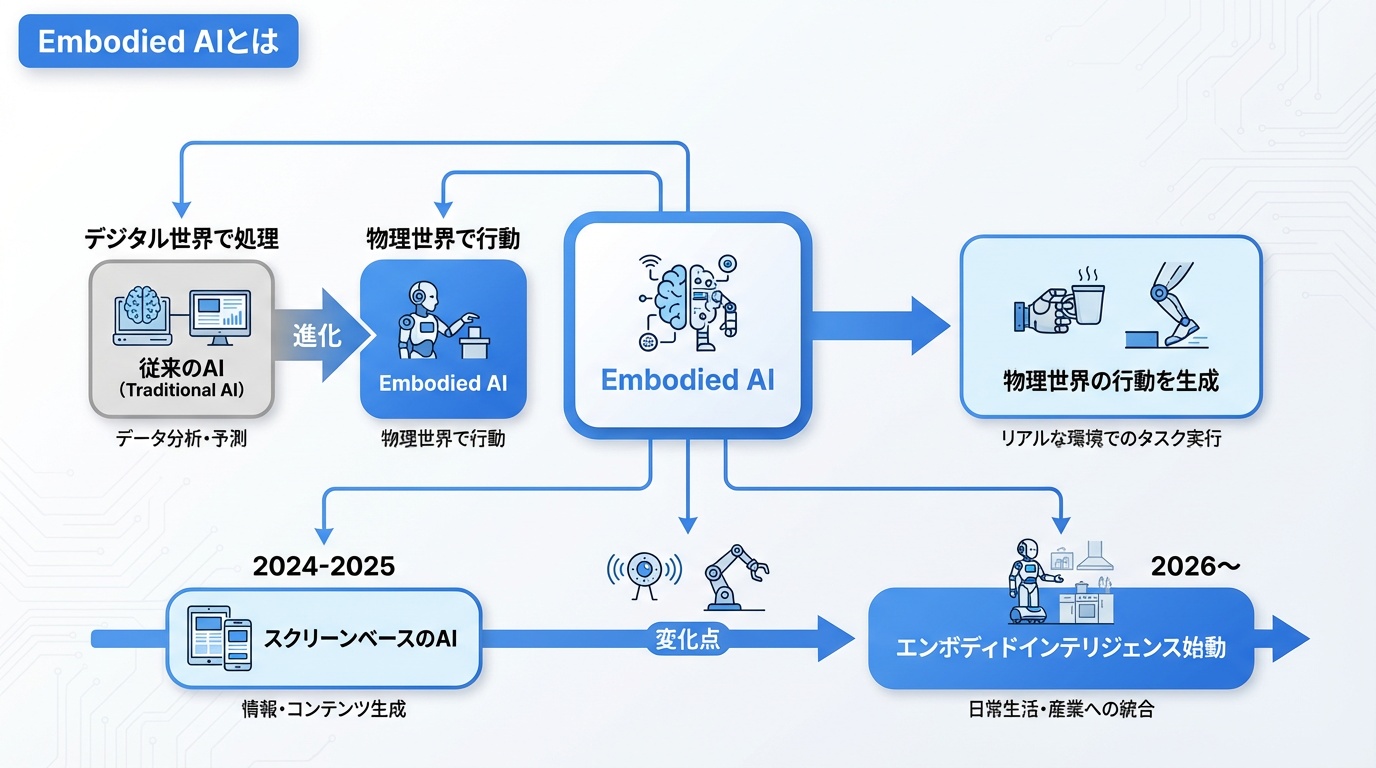

Embodied AIは、テキストや画像を生成するだけでなく、物理世界で「行動」できるAIです。ロボットの「頭脳」として機能し、センサー入力を処理して実際の動作を生成します。
従来のAIとの違い
| 項目 | 従来のAI(Generative AI) | Embodied AI(Physical AI) |
|---|---|---|
| 出力 | テキスト、画像、音声 | 物理的な動作、運動 |
| 環境 | デジタル空間 | 現実世界 |
| フィードバック | なし/限定的 | センサーによるリアルタイム |
| タスク | 情報処理 | 物理的マニピュレーション |
「チャットボット時代」からの転換
2024〜2025年は生成AIがスクリーン上で活躍した時代でした。2026年は、AIが画面から飛び出して物理世界で働く「Embodied Intelligence」の時代が始まっています。
Embodied AIの技術アーキテクチャ
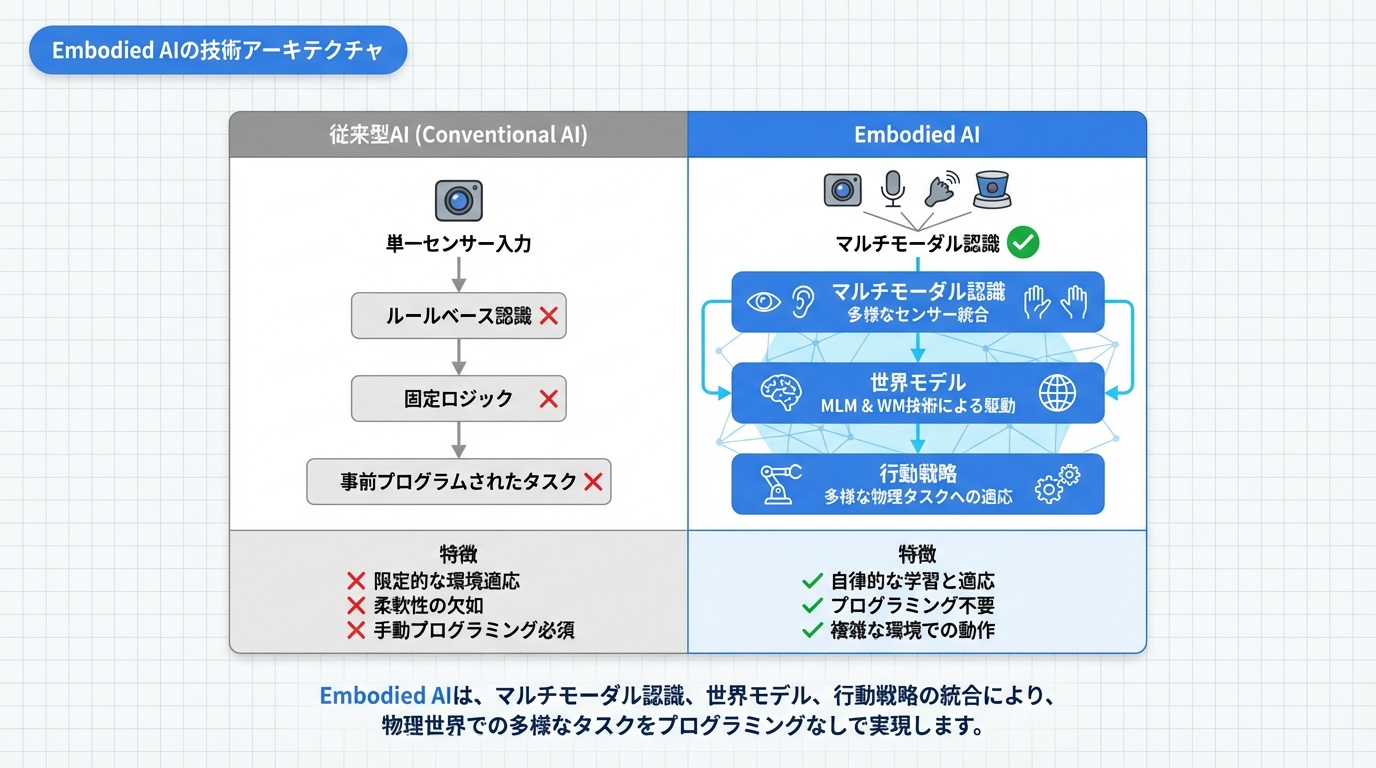
Embodied AIシステムは、複数の要素技術を統合した3層フレームワークで構成されます。
3層アーキテクチャ
- マルチモーダル知覚層: 視覚、聴覚、触覚などの複数センサーからの入力を統合
- ワールドモデル層: 環境の物理法則と状態を理解・予測
- 行動戦略層: 目標達成のための動作計画と実行
基盤モデルの役割
マルチモーダル大規模モデル(MLM)とワールドモデル(WM)の進歩がこの分野を変革しています。エンドツーエンドの学習システムにより、タスク固有のプログラミングなしで多様な物理タスクに対応できます。
主要な基盤モデルと企業
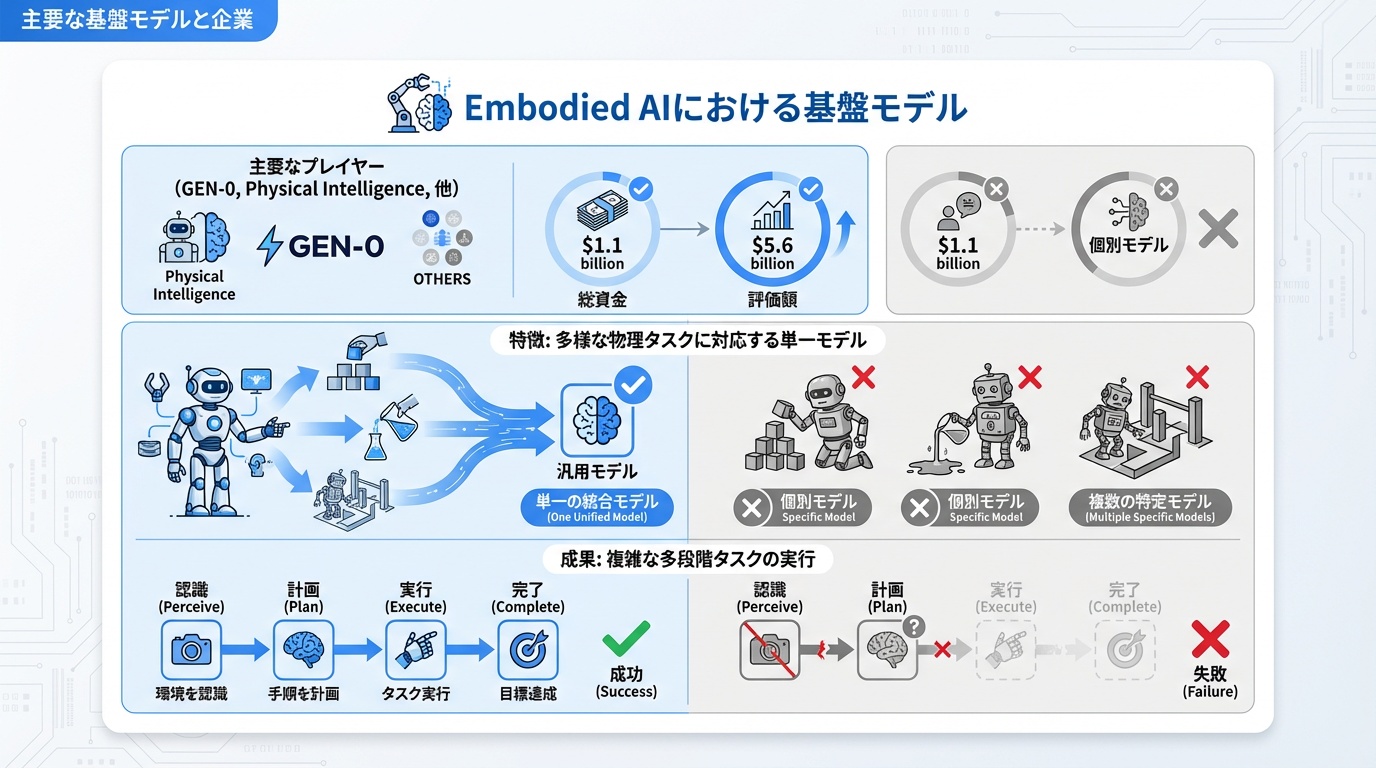
Embodied AI分野では複数の企業が基盤モデルの開発を競っています。
Physical Intelligence
- 累計調達額: 11億ドル
- 企業価値: 約56億ドル
- 特徴: 単一の汎用モデルで多様な物理タスクに対応
- 実績: コーヒーを13時間連続で入れ続けるなど、複雑なマルチステップタスクを実行
GEN-0(Generalist AI)
- 特徴: 高忠実度の物理インタラクションデータで直接訓練
- データセット: 史上最大・最多様な実世界マニピュレーションデータセット
- タスク範囲: ジャガイモの皮むきからボルト締めまで
その他の主要プレイヤー
- Google DeepMind: RT-2、Gemini Roboticsなど
- NVIDIA: GR00T基盤モデル
- OpenAI: ロボティクス研究再開
- Figure AI: Helix VLAモデル
市場動向と投資トレンド
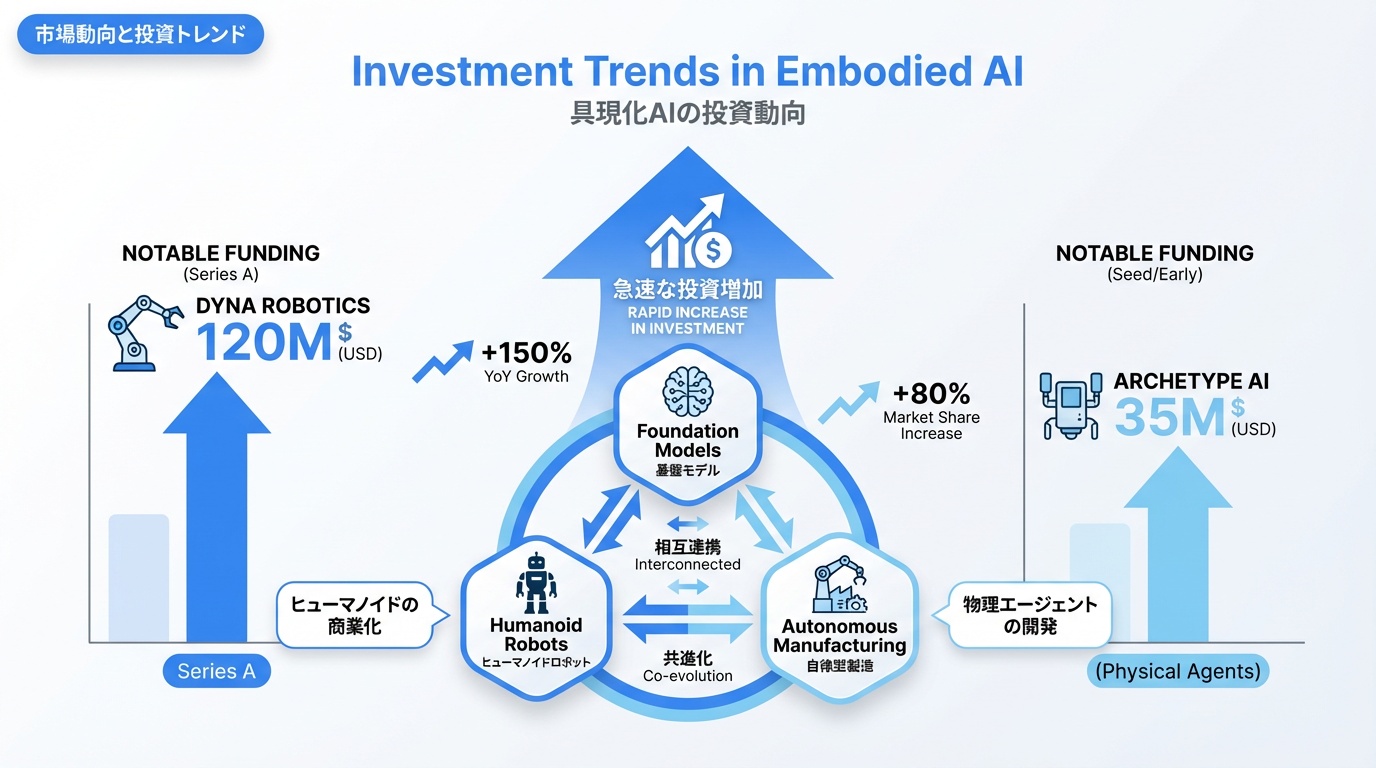
Embodied AI/ロボティクス分野への投資は急増しています。
投資推移
| 年 | 投資額 | 増加率 |
|---|---|---|
| 2023年 | 31億ドル | – |
| 2025年 | 72億ドル | +132% |
注目の投資領域
- ヒューマノイドロボット
- 基盤モデル
- 自律製造システム
主要な資金調達
- Dyna Robotics: シリーズAで1.2億ドル(基盤モデル開発)
- Archetype AI: 3,500万ドル(Physical Agents)
- Foxglove: 4,000万ドル(ロボット開発者向けデータプラットフォーム)
VLA(Vision-Language-Action)モデル
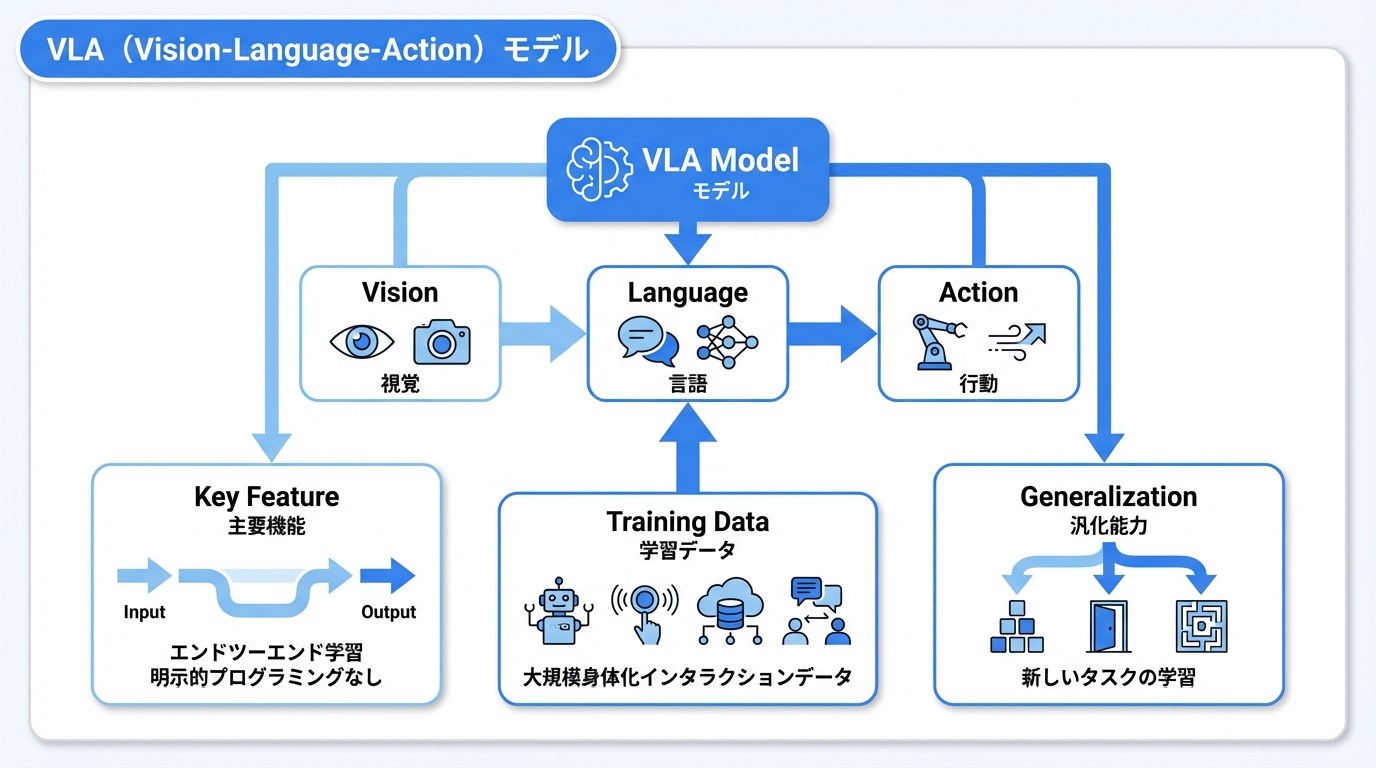
Embodied AIの核となる技術がVLAモデルです。
VLAの仕組み
- Vision(視覚): カメラ画像から環境を認識
- Language(言語): 自然言語でタスク指示を理解
- Action(行動): 具体的なロボット動作を生成
エンドツーエンド学習
大規模な身体化インタラクションデータで訓練されたVLAモデルは、明示的なプログラミングなしでタスクを学習。新しいタスクへの汎化能力も持ちます。
実世界での応用事例
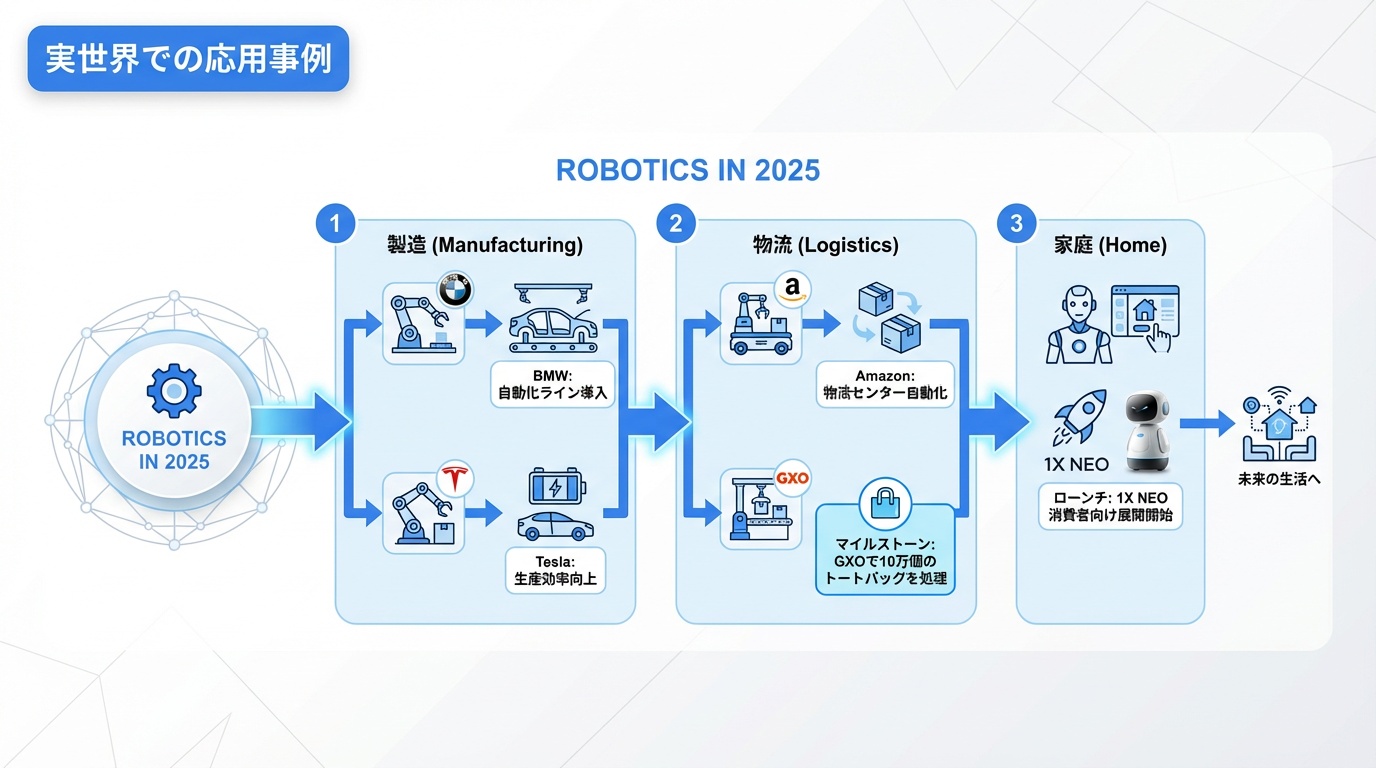
2025年はロボティクスが「クールなデモ」から「大規模導入」へ移行した年でした。
製造業
- BMW工場でのFigure 02運用
- Teslaギガファクトリーでの自社製Optimus
物流
- Amazon倉庫でのAgility Digit
- GXO施設での10万トート運搬達成
家庭
- 1X NEOの消費者向け展開開始
課題と限界
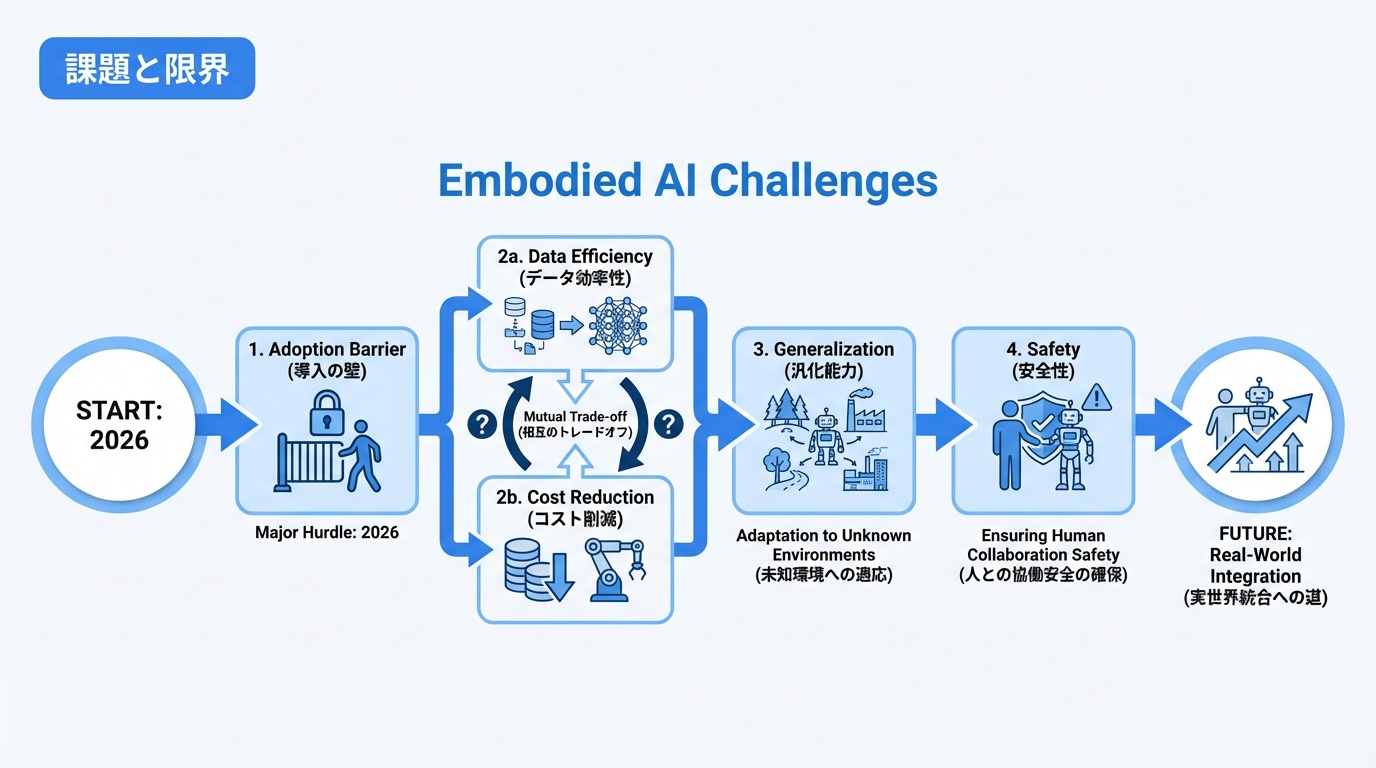
Embodied AIには依然として大きな課題があります。
「導入の壁」
2026年はEmbodied AIが「導入の壁」にぶつかる年とも予測されています。魅力的なデモと、人間の介入なしに1万回連続で動作する信頼性の高いシステムとの間には、大きなギャップがあります。
主な課題
- データ効率: 実世界データの収集コスト
- 汎化能力: 未知の環境への適応
- 安全性: 人間との協働における安全確保
- コスト: ハードウェアと運用のコスト削減
今後の展望
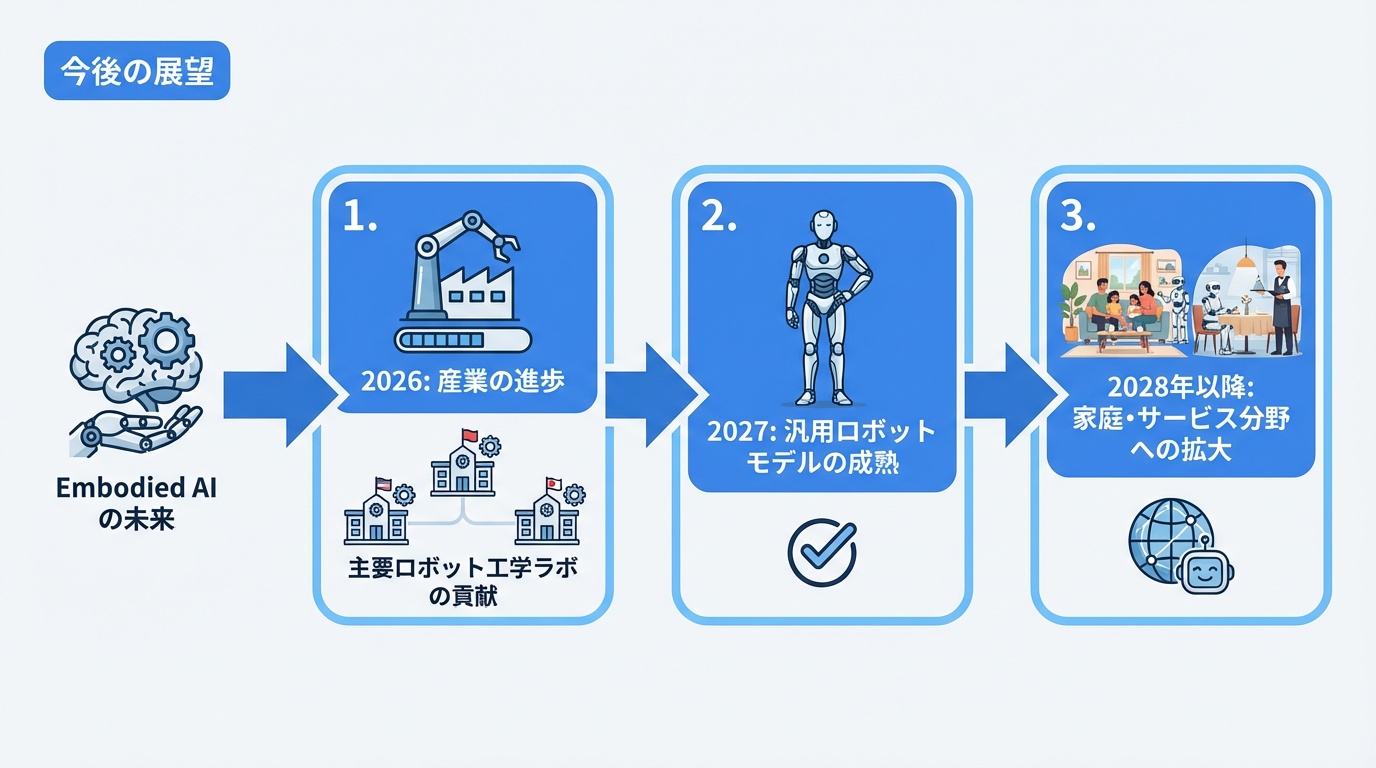
Embodied AI分野は急速に進化を続けています。
2026年の予測
- 主要ロボティクスラボ(Google DeepMind、NVIDIA、Physical Intelligence、Figure、OpenAI、Boston Dynamicsなど)のうち少なくとも3社が、同一ベンチマークで結果を公開
- 製造・物流での本格導入拡大
- 基盤モデルの性能向上と標準化
長期展望
- 2027年: 汎用ロボット基盤モデルの成熟
- 2028年以降: 家庭・サービス業への本格展開
まとめ

Embodied AI(身体性AI)は、AIがデジタル世界から物理世界へ進出する次のフロンティアです。Physical Intelligence、Generalist AI、NVIDIAなどの基盤モデル開発企業を中心に、急速な技術進歩と大規模投資が進んでいます。
2025年に「デモから導入へ」の転換が始まり、2026年は真の実用化が試される年となります。製造業・物流での成功事例を足がかりに、Embodied AIは社会インフラを支える技術として成長していくでしょう。
https://ainow.jp/nvidia-groot-guide/

https://ainow.jp/nvidia-groot-guide/


https://ainow.jp/soft-robotics-guide/

https://ainow.jp/telepresence-robot-guide/