
AINow(エーアイナウ)編集部です。現代のAI技術の根幹をなすニューラルネットワークは、人間の脳の働きを模倣した情報処理システムとして急速に発展しており、その仕組みや応用例は今後の技術革新において必須の知識となります。本記事では、ニューラルネットワークの基本構造からその動作原理、学習手法、さらにはディープラーニングとの関係や実用例、代表的なモデルの種類、そして歴史や今後の課題に至るまで、幅広い視点から詳しく解説します。
各セクションでは具体例や最新の研究成果、業界の動向も合わせて紹介しているため、技術者はもちろん、技術に興味がある一般読者の方にも多くの知見と実践的な情報を得ることができる内容となっています。
【サマリー】本記事では、ニューラルネットワークの基本から最新の研究動向、具体的な応用例、さらにはディープラーニングとの比較や歴史、そして今後の課題とその解決策について、豊富な具体例と補足情報を交えながら解説します。これにより、読者はAI技術の根幹をなすニューラルネットワークの全体像を理解し、最新の研究成果や応用ケースに触れることができます。
ニューラルネットワークとは
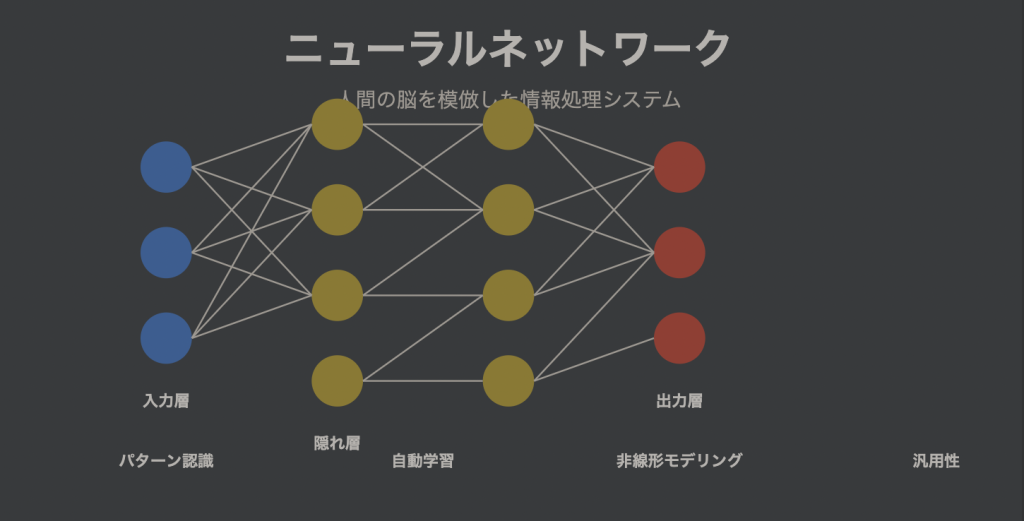
ニューラルネットワークは、人間の脳内の神経細胞(ニューロン)の動作を模倣して設計された情報処理システムです。この構造は、複雑なパターンや非線形な関係性を持つデータの認識・学習に非常に適しており、従来の統計手法では困難だった課題を解決するために開発されました。具体的には、膨大な量のデータから特徴量を自動的に抽出し、分類や予測を行うことができるため、画像認識、自然言語処理、音声認識などの多岐に渡る分野で採用されています。
2025年の現状では、ニューラルネットワークは高精度な医療診断システムや自動運転システム、さらには生成AIの応用など、ビジネスや科学研究の現場においても革新的な成果を上げています。例えば、最新の生成AIの基本技術は、このニューラルネットワークを基盤として実現され、その応用範囲は年々拡大しています。
ニューラルネットワークの基礎
ニューラルネットワークは、基本的に「入力層」「隠れ層」「出力層」という三層構造で構成されています。各層には多数のノード(またはニューロン)が存在し、これらのノードが互いに重みを持って接続されています。入力層にデータを投入すると、隠れ層がその特徴を抽出し、最終的に出力層が予測や分類結果を返します。
各ノード間の「重み」と呼ばれるパラメータと「バイアス」が学習によって最適化されることで、モデルは段階的にパターン認識能力を向上させます。
さらに、ニューラルネットワークは複雑な非線形問題を解決する能力に優れており、従来の線形アルゴリズムでは困難だった問題に対しても強力な解法を提供しています。例えば、画像処理の分野ではCNN(畳み込みニューラルネットワーク)が、自然言語処理の分野ではRNNやTransformerといったモデルが、高い性能を発揮しています。
人間の脳とニューラルネットワークの関係
ニューラルネットワークは、人間の脳の仕組み・構造にヒントを得ています。人間の脳は約860億個のニューロンが相互に結合し、複雑なネットワークを形成することで情報処理や学習、記憶保持を実現します。これに対し、現代のニューラルネットワークも多数の計算ノードが階層的に連結されることで、情報抽出と意思決定を行っています。
ただし、実際の人間の脳は高い柔軟性を持ち、新たな知識を学習しながらも既存の情報を維持する能力(可塑性と安定性のバランス)に長けていますが、ニューラルネットワークはしばしば「破滅的忘却」の問題に直面し、新しいタスクを学習すると以前の学習内容が失われるという課題があります。2025年には、連続学習やメタ学習の研究が進展し、この問題への対策が着実に進んでいます。
ニューラルネットワークの仕組み
ニューラルネットワークの動作原理を理解することは、その応用範囲と限界を正確に捉える上で重要です。ここでは、基本的な構造と学習プロセスを詳しく解説し、実際のシステムへどのように応用されているかを具体例を交えて紹介します。例えば、ChatGPTの活用にもこの理論が応用されており、自然な対話生成が実現されています。
入力層、隠れ層、出力層の役割
ニューラルネットワークは通常、以下の3層に分類されます:
- 入力層:外部からのデータを受け取り、数値や特徴量として表現する層
- 隠れ層:入力データの抽象的な特徴を捉え、情報変換を行う層
- 出力層:最終的な予測値や分類結果を提供する層
具体的には、入力層では画像認識タスクの場合、各ピクセルの輝度値や色値などが入力データとして与えられ、隠れ層を通して抽象度の高い情報へと変換されます。出力層では、例えば複数のクラスに対する確率が算出され、分類結果が決定されます。最新のニューラルネットワークモデルでは、2025年においては数百から数千の層を持つ超深層ネットワークも開発され、非常に複雑なタスクにも対応できるようになっています。
重みとバイアスの調整方法
ニューラルネットワークの学習は、各ノード間の「重み」と「バイアス」を最適化するプロセスに依存しています。重みは、各ノード間の接続強度を示し、重要な特徴には大きな値が割り当てられ、バイアスは各ノードの活性化を制御するための定数項として機能します。これらのパラメータは、フォワードパスで出力を得た後、誤差を計算し、バックプロパゲーションと呼ばれる手法で逆伝播されながら調整されます。
- フォワードパス:入力データをネットワーク内に流し、出力を得る
- 誤差計算:出力と正解との差を算出し、誤差を定量化する
- バックプロパゲーション:誤差勾配を計算し、その情報を元に重みとバイアスを修正する
最新の研究では、Adaptive Learning Rateのような技術が取り入れられ、学習率を自動調整することにより、より高速かつ正確な学習が実現されています。さらに、NVIDIA AI技術の進歩や最新のGPUチップの登場により、大規模なニューラルネットワークの学習が効率化されている点も見逃せません。
活性化関数の役割
活性化関数は、各ノードの出力を決定する重要なコンポーネントであり、非線形性をネットワークに導入するために使用されます。これにより、単純な線形変換だけでは捉えきれない複雑なパターンを学習することが可能となります。具体的には、次の役割があります:
- 非線形性の導入:複雑なパターンや関係性を学習可能に
- 出力の正規化:計算された値を一定の範囲に収め、過度な値の発散を防ぐ
- 勾配の制御:学習中の勾配消失や爆発のリスクを軽減
代表的な活性化関数として、ReLU(Rectified Linear Unit)、Sigmoid、tanhなどが知られており、2025年には新たにSwishやGELUといった関数がさまざまなタスクで採用されています。これらの関数は、計算コストが低く、学習の安定性を高める効果も期待され、実務上は非常に重要な役割を果たしています。
誤差逆伝播法の基本
誤差逆伝播法(バックプロパゲーション)は、ニューラルネットワークにおける学習の核心をなす手法です。この手法は、ネットワークの出力から生じた誤差を逆方向に伝播させ、各パラメータの寄与度を計算することで、重みやバイアスの修正を行います。これにより、モデルは次第に正確な予測を行う能力を身につけるのです。
このプロセスには以下のステップが含まれます。まず、出力層での誤差を計算し、次にこの誤差をネットワーク内で逆伝播させながら、各パラメータに対する勾配を求めます。最終的に、学習率を用いてパラメータを更新し、誤差を最小化するように調整されます。
2025年現在、Synthetic Gradientsのような新技術も登場し、並列計算効率が向上することで大規模ネットワークの学習時間を大幅に短縮できるようになっています。
ニューラルネットワークの学習手法
ニューラルネットワークの性能は、使用される学習手法に大きく左右されます。本セクションでは、教師あり学習、教師なし学習、さらには半教師あり学習や自己教師あり学習といった手法の特徴、具体的な利用シーン、及びそれぞれのメリット・デメリットについて、最新の動向とともに解説します。実際、企業の生成AI活用事例も参考にしながら、最適な手法の選択が求められています。
教師あり学習と教師なし学習の違い
ニューラルネットワークの学習手法は、大別すると「教師あり学習」と「教師なし学習」に分けられます。教師あり学習では、入力と正解ラベルのペアを用いるため、分類や回帰といった問題に向いており、画像認識や音声認識などで広く活用されています。一方、教師なし学習は、正解ラベルが存在しないデータから隠れたパターンや構造を発見するため、クラスタリングや次元削減などに適用されます。
2025年の最新技術では、半教師あり学習や自己教師あり学習と呼ばれる手法も注目され、ラベル付きデータが少ない状況でも高精度な学習が可能になっています。これらの手法は、それぞれの特性を活かしながら、幅広い応用シーンで効果を発揮しています。
確率的勾配降下法
確率的勾配降下法(SGD: Stochastic Gradient Descent)は、ニューラルネットワーク最適化の基礎手法として広く採用されています。SGDは、大規模データセットの一部を利用して勾配を計算し、パラメータを逐次的に更新することで効率的な学習を実現します。その特性として、大量データを小分けに扱うことにより、局所解から抜け出す能力があり、最適解に向けた探索が進みやすいというメリットがあります。
また、MomentumやAdaGrad、Adamといった改良版の手法も提案され、2025年現在ではLookahead Optimizerなど、さらに高度な最適化技術が研究されています。これらは、大規模ネットワークやリアルタイムアプリケーションにおける学習の安定性と効率向上に寄与しています。
ドロップアウト法による過学習防止
過学習(オーバーフィッティング)は、モデルが訓練データに対して過度に最適化され、未知のデータに対しての汎化性能が低下する問題です。ドロップアウト法は、学習時にランダムにノードの一部を無効化することで、特定のパターンに依存しすぎることを防止し、モデルの汎用性を向上させる技術です。この手法により、実際の応用での性能向上が期待できるため、2025年でも多くの実装例が見られます。
さらに、Spatial DropoutやVariational Dropoutといった進化形も提案され、異なるタスクやネットワーク構造に対してより効果的に過学習を防ぐアプローチが研究されています。
各手法のメリットとデメリット
ニューラルネットワークにおける各学習手法は、一長一短が存在し、タスクやデータの性質に応じた適切な手法の選択が求められます。以下の表は、主要な手法のメリットとデメリットをまとめたものです。
| 手法 | メリット | デメリット |
|---|---|---|
| 教師あり学習 | ・明確な目的に対して高精度な予測が可能 ・結果の解釈が比較的容易 | ・大量のラベル付きデータが必要 ・データラベリングに高コスト |
| 教師なし学習 | ・ラベルなしデータから潜在的なパターンを発見 ・未知の構造の発見に適用 | ・結果の解釈が難しいことがある ・タスクにより精度が限定的 |
| SGD | ・大規模データセットに対して効率的 ・局所解からの脱出がしやすい | ・ハイパーパラメータの調整が難しい ・収束が不安定になる場合がある |
| ドロップアウト | ・過学習を効果的に抑制 ・実装が比較的シンプル | ・学習時間の延長 ・最適なドロップアウト率の設定が必要 |
また、最新のAutoML技術を活用することで、これらの手法を自動的に選択・調整する試みも進んでおり、専門的な知識がなくても高性能なニューラルネットワークを構築できる時代が到来しています。例えば、企業の生成AI活用事例において、こうした自動最適化技術が実際に活用されています。
ディープラーニングとの関係
ニューラルネットワークとディープラーニングは、互いに密接な関係を持ちながらも明確に区別される概念です。ディープラーニングは、多層のニューラルネットワークを利用して、特徴抽出や予測を自動化する技術として発展してきました。この手法は、従来のアルゴリズムでは捉えにくかった複雑な非線形パターンを学習する点に優れており、最新のモデルの多くはディープラーニング技術をベースにしています。
ディープラーニングの定義と特徴
ディープラーニングは、通常3層以上の隠れ層を有する多層化されたニューラルネットワークの一種です。主な特徴には、自動的な特徴抽出、end-to-end学習、大量のデータおよび計算リソースの必要性が挙げられます。これにより、ディープラーニングは画像認識、自然言語処理、音声認識など、従来技術では難しかった領域で驚異的な性能を実現しています。
ディープラーニングの進化と応用例
ディープラーニングは2000年代半ばから急速に発展し、2025年現在では、コンピュータビジョン、自然言語処理、音声認識、そして医療や金融分野における応用例が数多く報告されています。たとえば、コンピュータビジョンでは自動運転車における障害物認識や顔認識、医療画像診断での病変検出などが挙げられ、最新の研究ではStable Diffusionなどの技術も応用されています。これにより、画像、テキスト、音声など複合的なデータを統合的に扱うマルチモーダル学習が前進し、より豊かな情報抽出が可能となっています。
ニューラルネットワークとの違い
一般に、ニューラルネットワークという用語は、隠れ層の数が少ない従来型のネットワークを指す場合があり、ディープラーニングはその中でも多層構造を持つ手法として区別されます。具体的には、ニューラルネットワークは1〜3層程度の隠れ層を持つのに対し、ディープラーニングは3層以上、時には数百層に及ぶ構造が採用されるため、より複雑な特徴抽出や学習が可能となります。また、ディープラーニングは学習の自動化や大規模データの処理が前提となっており、データ量と計算資源の点でも大きな違いが存在します。
2025年現在、これらの境界はますます曖昧になっており、ニューラルネットワークの発展とディープラーニングは密接に連携しながら今後も進化していくでしょう。例えば、RAG技術はその融合の一例として注目されています。
ニューラルネットワークの実用例
ニューラルネットワークはその高い柔軟性と学習能力により、様々な分野で実用的な応用が進んでいます。ここでは、画像認識、自然言語処理、自動運転、そして医療分野における具体的なケースを紹介し、各分野での最新技術や導入事例についても触れていきます。
画像認識への応用
画像認識は、ニューラルネットワーク、特に畳み込みニューラルネットワーク(CNN)が大きな成果を挙げた応用分野です。顔認識システムは、空港や各種施設でのセキュリティ管理、スマートフォンの顔認証などに利用され、また医療現場ではX線やMRI画像からの異常検出による診断補助にも広く使われています。さらに、自動運転技術における道路標識認識や歩行者検出、そして製造業での品質管理といった分野にも応用されています。
これらの技術は、画像生成技術(例えばGANsを用いた超解像やスタイル転送)などと結びつき、常に進化を遂げています。
自然言語処理での使用例
自然言語処理(NLP)の分野では、ニューラルネットワークの採用により、機械翻訳、チャットボット、感情分析、テキスト要約などのタスクで画期的な成果が上がっています。Google翻訳やDeepLなどのオンライン翻訳サービスがその代表例であり、また、カスタマーサポート自動化のためにAIアシスタントを活用する動きも活発です。特に、GPT-3やその後継モデルを用いたチャットボットは、複雑な文脈の理解や自然な会話生成が可能となり、利用シーンが飛躍的に広がっています。
最新の取り組みとしては、AIチャットボット技術の進化があり、より高機能で自然な対話システムが注目されています。
自動運転技術への貢献
自動運転技術は、ニューラルネットワークを使った環境認識、経路計画、運転制御、予測と意思決定において大きな進展を見せています。具体的には、物体検出により他の車両、歩行者、障害物を把握し、セマンティックセグメンテーションで道路と非道路領域を正確に区別します。経路計画では、最適なルート選択や動的な経路変更が実現され、運転制御ではステアリング、アクセル、ブレーキの自動調整が行われます。
現在、2025年には一部の都市ですでに自動運転タクシーの商用サービスが開始されており、ニューラルネットワークの進化が実用段階に達していることが伺えます。特に、End-to-End学習の技術は今後さらなる飛躍を期待できる分野です。
医療分野での活用事例
医療分野におけるニューラルネットワークの応用は、診断の精度向上や創薬、遺伝子解析、手術支援など、さまざまな形で現れています。X線やCT、MRI画像を用いた画像診断支援システムは、病変検出や異常部位の自動セグメンテーションを実現し、診断工程の効率化に大きく寄与しています。また、電子カルテデータの解析により患者の健康リスク予測や治療効果の最適化も進んでおり、最近では医療AIの導入が多くの医療機関で確認されています。
これらの技術は、倫理的な検討や法的規制と並行して進められ、医療現場での信頼性と安全性を確保するための取り組みが進行中です。
代表的なニューラルネットワークの種類
ニューラルネットワークには、用途や目的に応じたさまざまな種類が存在し、各モデルは特定のタスクに対して最適な性能を発揮します。以下では、ディープニューラルネットワーク(DNN)、畳み込みニューラルネットワーク(CNN)、再帰型ニューラルネットワーク(RNN)、生成型対向ネットワーク(GAN)、オートエンコーダ(Autoencoder)など、主要なモデルの特徴と応用例を詳しく解説します。
ディープニューラルネットワーク (DNN)
ディープニューラルネットワーク(DNN)は、複数の隠れ層を持つフィードフォワード型のネットワークであり、音声認識、自然言語処理、推薦システムなど、様々な分野で利用されています。DNNの特徴として、非線形の活性化関数の導入により、複雑なパターンの抽出と高度な特徴学習が可能となる点が挙げられます。2025年現在、一部のモデルは数百層に及び、極めて複雑なタスクにも対応できる能力を持っています。
ただし、層が深くなることで勾配消失問題が発生するため、ReLUや残差接続(ResNet)といった手法が実装されており、これにより学習効率が大幅に向上しています。
畳み込みニューラルネットワーク (CNN)
畳み込みニューラルネットワーク(CNN)は、主に画像処理に特化したネットワークで、局所的な特徴抽出とプーリング層による次元削減により、画像中の重要なパターンを効率良く識別します。CNNは、物体認識、顔認識、医療画像診断など様々な応用に利用され、さらに最新の研究ではAttention Mechanismを組み込んだモデルが提案されるなど、技術革新が続いています。なお、AIによる画像生成分野でも、CNNはGANsと連携して新たな可能性を引き出しています。
再帰型ニューラルネットワーク (RNN)
再帰型ニューラルネットワーク(RNN)は、時系列データや系列データの処理に適しており、内部状態を持つことで過去の情報を保持します。これにより、自然言語処理や音声認識、時系列予測などで高い性能を発揮します。従来のRNNの長期依存性の問題は、LSTM(Long Short-Term Memory)やGRU(Gated Recurrent Unit)の登場により大きく改善され、2025年現在ではこれらの改良型モデルが実務で広く用いられています。
また、TransformerアーキテクチャはRNNの代替として、並列処理に優れた点からNLP分野で主流となりつつあります。
生成型対向ネットワーク (GAN)
生成型対向ネットワーク(GAN)は、生成器と識別器という2つのネットワークが互いに競い合うことで、高品質なデータの生成を可能にする革新的なモデルです。GANは、画像生成や画像変換、データ拡張において驚異的な成果を上げており、2025年には条件付きGANやCycleGANといった発展型モデルが注目されています。これにより、教師なし学習においても、具体的な目的に応じた画像やデータの生成が可能になっています。
オートエンコーダ (Autoencoder)
オートエンコーダは、入力データを低次元の表現に圧縮し、その後元のデータに再構成することで、特徴抽出や次元削減、ノイズ除去、異常検知に活用される教師なし学習の一手法です。近年では、変分オートエンコーダ(VAE)や条件付きオートエンコーダなど、生成モデルとしての能力も強化されており、新たなデータ生成や補間の可能性が追求されています。これらの技術は特に、データの本質的な特徴抽出や表現学習分野で重要な役割を果たしています。
このように、各代表的なニューラルネットワークは、それぞれの特性を活かして特定の分野で最適な実装が行われており、実用システムにおいては複数のモデルを組み合わせたハイブリッドアプローチも採用されています。例えば、最新のAI研究では、CNNとTransformerを組み合わせたVision Transformerが画像認識分野で注目を集めています。
ニューラルネットワークの歴史
ニューラルネットワークの研究は、人工知能全体の発展と並行して進化してきました。ここでは、初期のパーセプトロンの登場から現代のディープラーニング確立に至るまでの主要な発展段階を振り返り、その進化の流れを詳しく解説します。
パーセプトロンの登場と進化
- 1943年:McCullochとPittsが人工ニューロンモデルを提案
- 1958年:Frank Rosenblattがパーセプトロンを発表
- 単層モデルとしてシンプルな構造
- 線形分離可能な問題の解決に寄与
- 1969年:Minskyらによる「パーセプトロンの限界」指摘
- XOR問題が解決できない点を証明
- AI研究の一時低迷(「AIの冬」)につながる
パーセプトロンの登場は、機械学習の可能性を示す革新的な出来事でしたが、その限界が明らかになることで一時期の停滞を招きました。しかし、その後のバックプロパゲーションの再発見が、ニューラルネットワーク研究の復興をもたらしました。
バックプロパゲーションの再発見
- 1974年:Werbosがバックプロパゲーションのアイデアを提案
- 1986年:Rumelhartらがこの手法を再評価・普及
- 多層パーセプトロンの効率的学習を実現
- 非線形問題の解決能力が大幅に向上
バックプロパゲーションの導入により、ニューラルネットワークは複雑な非線形問題に対しても高い性能を発揮できるようになり、ディープラーニングブームの礎を築きました。
ディープラーニングの確立
- 2006年:Hintonらによる深層信念ネットワークの提案
- 事前学習を活用した効率的なディープネットワークの学習手法を提案
- 2012年:AlexNetがILSVRCで圧倒的な性能を示す
- CNNの有用性を実証し、ディープラーニングブームの起点となる
- 2014年:GANの提案により生成モデルが革新
- 2017年:Transformerの登場でNLP分野に大きなブレイクスルー
- GPT、BERTなど現代の強力な言語モデルの基礎に
ディープラーニングの確立により、ニューラルネットワークは画像認識、自然言語処理、音声認識などの分野で人間の能力を超えるパフォーマンスを発揮するようになりました。
現在の研究と未来に向けて
2025年現在、ニューラルネットワーク研究は以下の方向性で進行中です:
- モデルの効率化
- 少ないデータと計算リソースで高精度な学習を実現する手法の開発(例:エッジAI対応の軽量モデル)
- Azure生成AIのようなクラウドベースのソリューションが支援
- 解釈可能性の向上
- ブラックボックス化したモデルの判断プロセスを説明可能にするXAI技術の発展
- 説明可能AI(XAI)の研究により、医療や金融などの分野で法的要件に対応
- マルチモーダル学習
- 画像、テキスト、音声など、複数のモダリティを統合して学習する手法の開発
- メタ学習・転移学習
- 少量データでの学習や、新しいタスクへの迅速な適応を可能にする手法の研究
- 自己教師あり学習
- ラベルなしデータを効果的に活用するための手法、例えば、自己生成的なラベル付け
これらの最新の研究開発により、ニューラルネットワークの応用範囲は急速に広がっており、ChatGPTの活用のような先端事例が日々生まれています。さらに、TransformerやNeural Architecture Searchなどの技術革新により、これまでにない柔軟で効率的なシステムが実現される見込みです。
今後もニューラルネットワークは、私たちのAI社会の中核を担う技術として、継続的な発展とともに多方面での応用が期待されています。
ニューラルネットワークとAI技術の関係
ニューラルネットワークは、現代AI技術の中心となる要素です。機械学習、ディープラーニングといった技術の根幹を成し、それぞれの分野で密接に連携しています。ここでは、これらの違いや共通点、及びAI全体の進化におけるニューラルネットワークの役割について詳しく解説します。
機械学習とディープラーニングの違い
機械学習は、データからパターンや法則を学習して予測を行う広義の技術であり、決定木、サポートベクターマシン、k近傍法など、様々なアルゴリズムが含まれます。一方、ディープラーニングは、これらの中でも多層のニューラルネットワークを用いた手法で、特徴抽出やパターン認識を自動的に実行する点に特徴があります。つまり、ディープラーニングは機械学習の発展形であり、ニューラルネットワークの応用範囲を大きく広げた技術です。
AI技術の進化におけるニューラルネットワークの役割
ニューラルネットワークは、その高いパターン認識能力により、画像認識、音声認識、自然言語処理、強化学習、生成モデルなど、さまざまなAI分野で中核的な役割を果たしてきました。さらに、GANsによる画像生成や、Transformerアーキテクチャによる文章生成など、新たな技術が次々と生み出され、AIシステムの性能と応用範囲を飛躍的に向上させています。これにより、例えば最新のAIサイト構築の事例にも反映され、産業全体での技術革新が加速しています。
AIとニューラルネットワークの未来の展望
2025年の未来に向けて、ニューラルネットワークは少数データ学習、説明可能性の向上、エッジAI、自己進化型AI、そして量子ニューラルネットワークなど、新たな技術領域に進出することが期待されています。例えば、AutoML-Zeroのような技術は、従来の人為的な設計に頼らず、最適な学習アルゴリズム自体を自律的に発見する試みとして注目されています。これにより、全く新しいAIシステムが創出され、人間とAIとの共生社会に向けた基盤技術としてさらに重要な役割を担うでしょう。
また、倫理的・社会的な視点からは、プライバシー保護やAIの公平性、雇用への影響などの課題に対して、制度的な枠組みと技術的な対応が進む必要があります。例えば、AI技術の進化による働き方の変革もその一例として取り上げられ、労働市場での新たな職種の創出などが現実のものとなりつつあります。
ニューラルネットワークの課題と解決策
ニューラルネットワークは多くの応用分野で優れた成果を上げていますが、一方で解決すべき多くの技術的課題も存在します。ここでは、計算資源の問題、データ準備、過学習、さらにはモデルの解釈性と透明性に焦点を当て、それぞれの課題とその解決策について詳しく解説します。
計算資源の問題
- 課題:
- 大規模なモデルの学習に膨大な計算資源が必要
- エネルギー消費と環境負荷の増大
- 解決策:
- モデルの軽量化:知識蒸留、プルーニング、量子化などの技術
- 専用ハードウェアの活用:TPU、NPU、そして最新のGPUチップ
- 分散学習:複数のマシンで並列処理を行うことで効率化
- グリーンAIの推進:エネルギー効率を重視したモデル設計
2025年現在、「カーボンニュートラルAI」に向けた研究が進み、CO2排出量の削減と同時に高性能を維持するための手法が模索されています。実際、一部の大手テクノロジー企業では、再生可能エネルギー100%のデータセンターを活用してAIモデルのトレーニングが行われています。
データの準備と前処理
- 課題:
- 豊富で高品質なデータの収集・整理の難しさ
- データの偏りやバイアスによるモデル低下
- 解決策:
- データ拡張技術:既存データから新たなサンプルを生成
- 転移学習:既存の豊富なモデルで少ないデータから学習
- フェデレーテッドラーニング:分散したデータをプライバシーを保護しながら活用
- アクティブラーニング:重要なデータの効率的収集と注釈付け
最近では、GANsを利用した「合成データ生成」技術も大きく進歩しており、プライバシー保護と高品質なトレーニングデータの両立が実現されています。詳細については、最新のAI研究も参照してください。
過学習とその対策
- 課題:
- モデルが訓練データに過剰適合し、汎化性能が低下する問題
- モデルの複雑性が上がるほど対策が必要
- 解決策:
- 正則化技術:L1/L2正則化、ドロップアウトの活用
- データ拡張:学習データの多様性を大幅に向上
- アンサンブル学習:複数モデルの予測を組み合わせ
- 早期停止:検証セットの性能をモニタリングし適切なタイミングで終了
2025年には適応的正則化技術が注目され、学習進行状況に応じて正則化強度を自動調整する手法が開発されています。これにより、過学習のリスクをさらに低減することが可能となっています。
モデルの解釈性と透明性
- 課題:
- ニューラルネットワークの内部判断プロセスがブラックボックス化している点
- AI決定の説明責任や法規制への対応が難しい
- 解決策:
- 説明可能AI(XAI):LIME、SHAPなどの手法を利用
- 注意機構(Attention Mechanism):モデルが注目している部分の可視化
- プロトタイプネットワークによる中間表現の解釈
- ルールベースのシステムとの統合でニューロシンボリックAIアプローチを推進
2025年現在、医療診断や信用評価などの重要な意思決定を伴う分野では、AIシステムが自らの判断根拠を人間に説明できることが法的にも求められており、モデルの解釈性向上は必須の課題となっています。実際、ある医療機関では、画像診断AIの解釈性向上技術を用い、医師との協業診断システムを実現しています。
これらの技術的課題への取り組みは、ニューラルネットワーク技術のさらなる発展と社会実装における鍵となり、倫理的・法的側面も併せて解決していく必要があります。
AI技術の進化は、私たちの働き方や生活様式に多大な影響をもたらし、より信頼性の高いシステムの構築を通じて、人間とAIの共生社会の実現に向けた取り組みが加速しています。
まとめ
ニューラルネットワークは、現代のAI技術の中核を成す画期的な技術であり、その進化は画像認識、自然言語処理、自動運転、医療など多岐にわたる分野で革新的な応用を実現しています。2025年には、ディープラーニングの技術がさらに洗練され、生成AIやTransformerをはじめとする最新技術との融合により、より高精度で効率的なシステムが普及しつつあります。
一方で、計算資源の膨大な消費、データ準備の困難さ、過学習、そしてモデルの解釈性という課題にも直面しており、研究者や開発者はこれらの問題を解決すべく日々努力を重ねています。これらの課題に対し、適応的正則化、分散学習、XAI技術などが次々と提案され、着実な進展が見られます。
今後もニューラルネットワークおよび関連するAI技術はさらなる発展を遂げ、人間社会に大きな変革をもたらすことが期待されます。技術の可能性を最大限に引き出しつつ、倫理的・社会的課題にも十分な対策が求められる中、私たちはこの技術の未来に注目しながら、共に進化していく責務を感じずにはいられません。


